Introduction
Welcome to the documentation for the “Extract data from PDF” Tool! This Tool is designed to automate the extraction of data from PDF files.
Whether you are a data analyst, researcher, or business professional, this Tool will assist you in effortlessly extracting valuable information
from PDF documents. With its powerful capabilities and user-friendly interface, this Tool is a great asset in the field of data extraction.
Overview
The “Extract data from PDF” Tool leverages advanced algorithms and machine learning techniques to extract data from PDFs. It eliminates the
need for manual data entry and saves you valuable time and effort. By automating the extraction process, this Tool ensures accuracy and efficiency
in handling PDF documents. With its intuitive design and robust features, it is the perfect solution for extracting data from PDFs of any size.
Key Features
-
Automated Data Extraction:
The “Extract data from PDF” Tool automates the process of extracting data from PDF documents. It analyzes the structure and content of the PDF to
identify and extract the relevant data points. This eliminates the need for manual data entry, reducing errors and saving you valuable time.
-
Data Point Customization:
The Tool allows you to customize the data points you want to extract from the PDF. Whether it is extracting invoice details, financial data, or customer
information, you can specify the data points you need. This flexibility ensures that you extract the specific information that is relevant to your analysis
or business needs.
-
Handling Image PDFs and difficult structure:
Relevance supports OCR for image PDFs and complex structures.
Use the Build page to access the set up and activate OCR - more details are provided in the Deep dive in the Tool section.
- Export and Integration:
The “Extract data from PDF” Tool allows you to export the extracted data in the CSV format. This enables seamless integration with other tools or systems,
making it easy to further analyze or process the extracted data.
Locate the Tool in the template page and click on Use template.
You can use the Tool as is or
clone it.
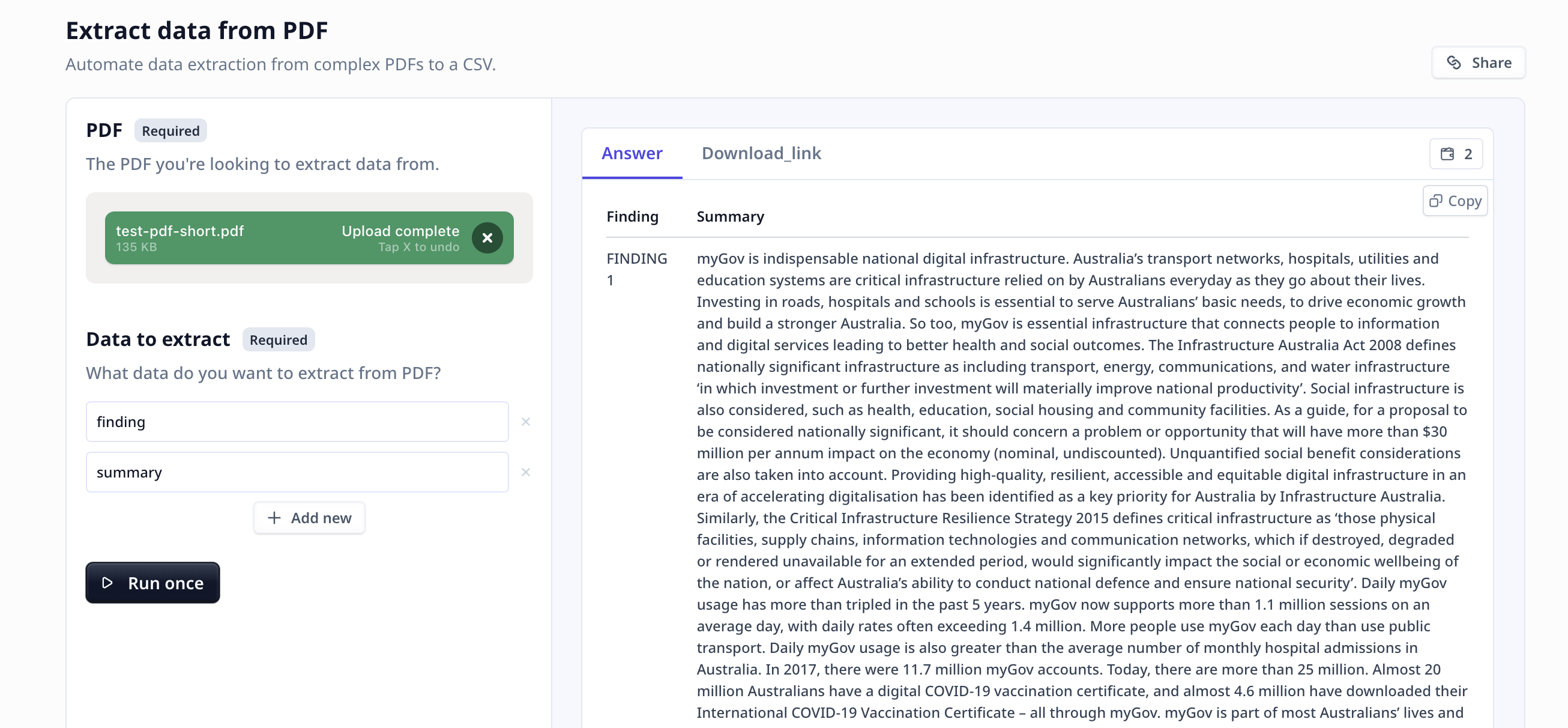
Follow these steps to extract data from your PDF documents:
-
Upload PDF: Upload the PDF file you want to extract data from.
-
Specify Data Points: Customize the data points you want to extract from the PDF. This could include fields such as “Legal name,” “Invoice number,”
“Invoice date,” “Bank details,” or “Invoice items breakdown.” Specify the data points that are relevant to your analysis or business needs.
LLMs are not designed or trained for statistical analysis. Hence, it is recommended
to ask for topics or subjects that are clearly mentioned in the text.
-
Run the Tool: Once you have uploaded the file and entered your data points, click the “Run Tool” button (on the App page) or use
the run options on your data table (bulk/single run) to initiate the the analysis process. The Tool will analyze the PDF document and
extract the specified data points. Sit back and relax while the Tool does the work for you.
Tools and templates can be
-
tested on individually provided inputs:
-
set to fetch the data from a dataset and apply the analysis on the whole dataset:
-
Export and Integrate: Click on “Export” and the extracted data be downloaded to your computer as a CSV file. This CSV contains
columns representing the extracted data. You can then integrate the data with other tools or systems for further analysis or processing.
If you clone
a template, or make a Tool from scratch, you will have access to the
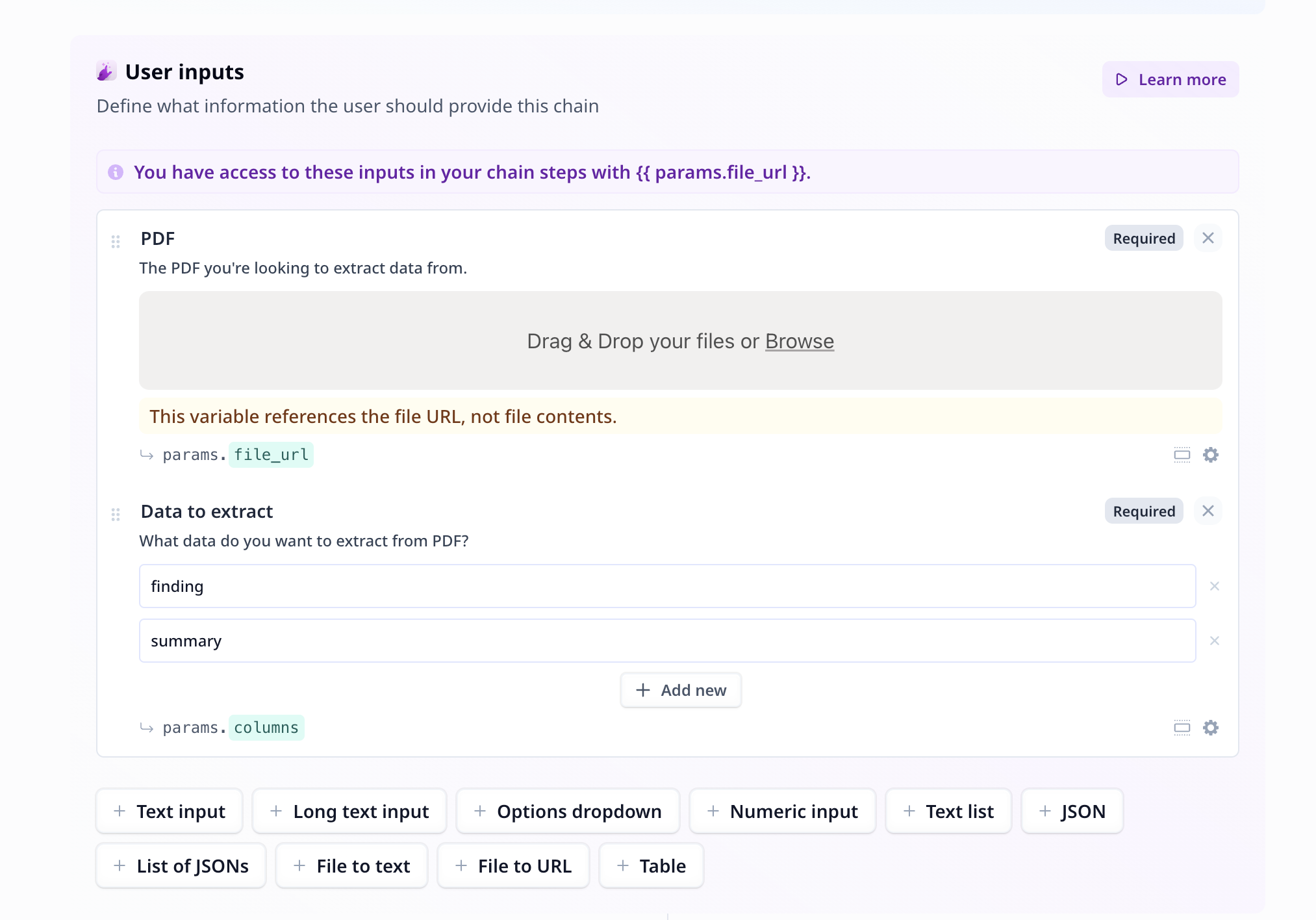
Build tab. Build is where one put together different components to build a Tool suitable for
their needs.
-
File to URL: An easy-to-use, one step component,
which takes care of all you need when uploading a file for further analysis.
-
Text list input: An input text component suitable
for entering a list of items, such as entering a list of topics or examples.
There are 5 components under the Tool steps in this analysis flow. These components take care of three
tasks: converting PDF to text, the LLM step, and formatting for CSV export.
Converting PDF to text
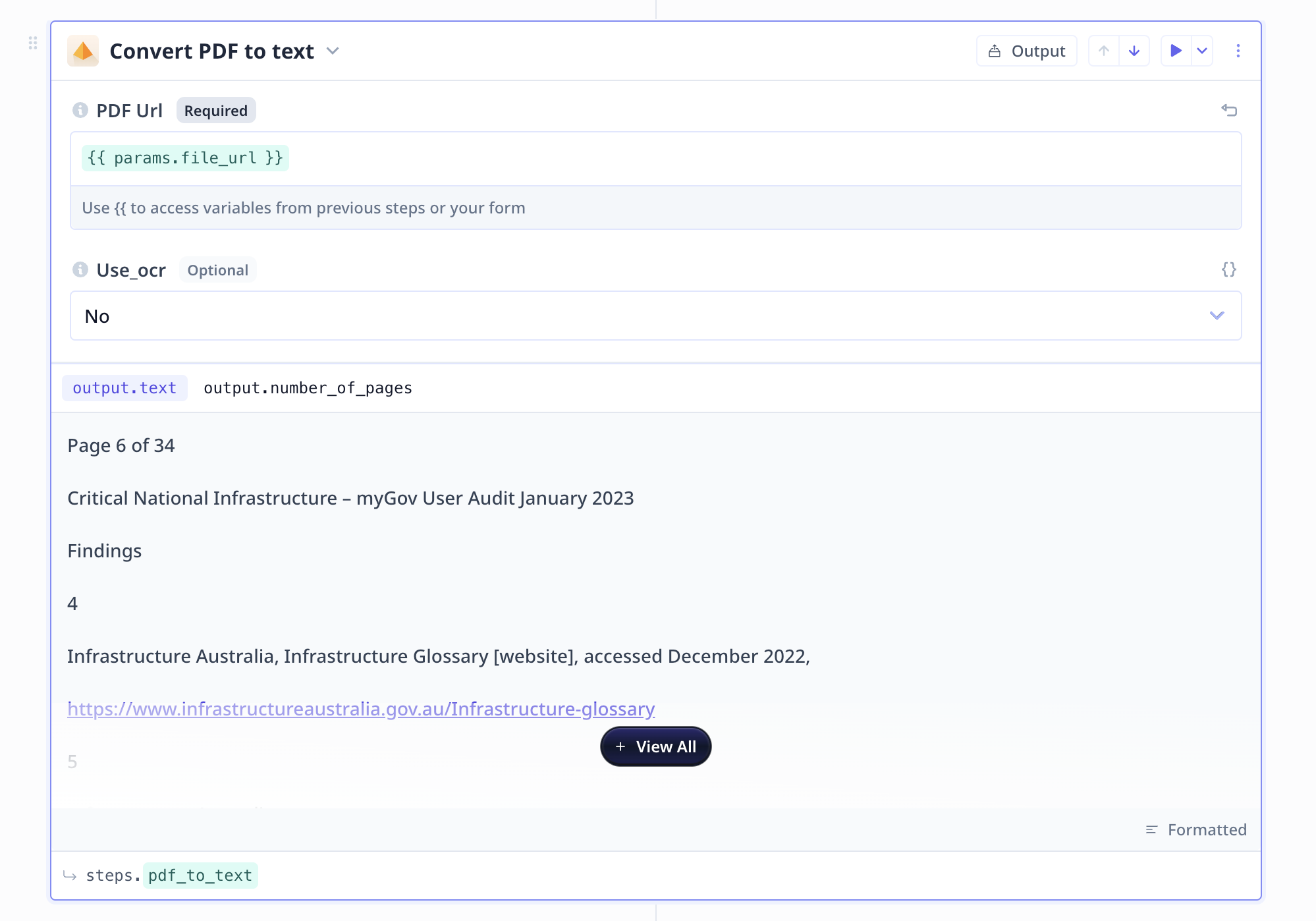 Text to PDF is a Tool step
supported by Rlevance AI, which receives a file URL and extract the text from it.
This component supports OCR.
Text to PDF is a Tool step
supported by Rlevance AI, which receives a file URL and extract the text from it.
This component supports OCR.
Large Language Model (LLM)
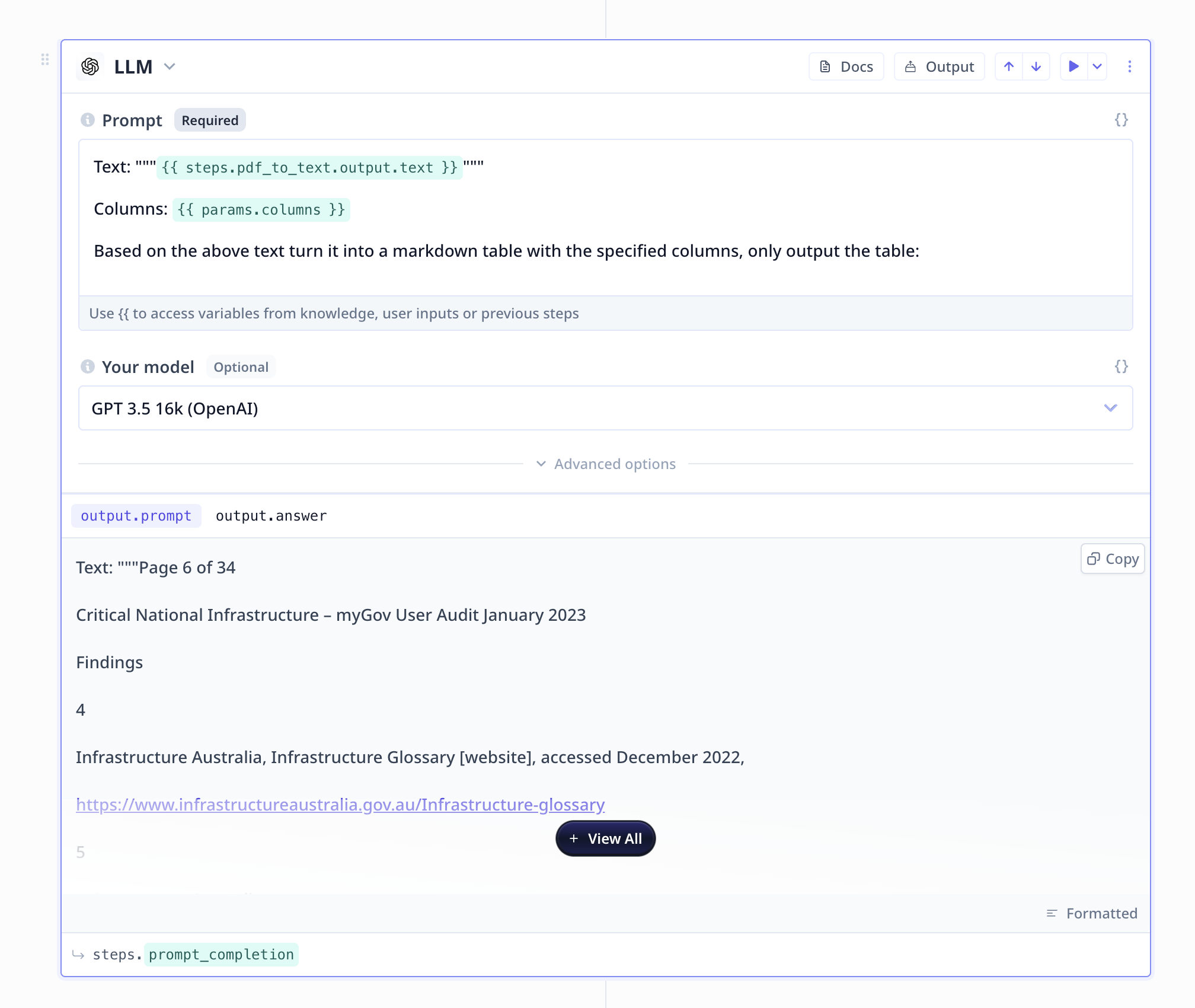 A large language model component is all set up to provide
you access to GPT (and many other LLMs).
In the prompt section, you will provide the required information as well as instructions to what
is expected to be done.
A Good Prompt
A large language model component is all set up to provide
you access to GPT (and many other LLMs).
In the prompt section, you will provide the required information as well as instructions to what
is expected to be done.
A Good Prompt
- Be short and precise with your instruction/request from the LLM
- Include formatting instruction when necessary
- Specify the scope using
", """ or similar identifiers
-
Markdown to CSV
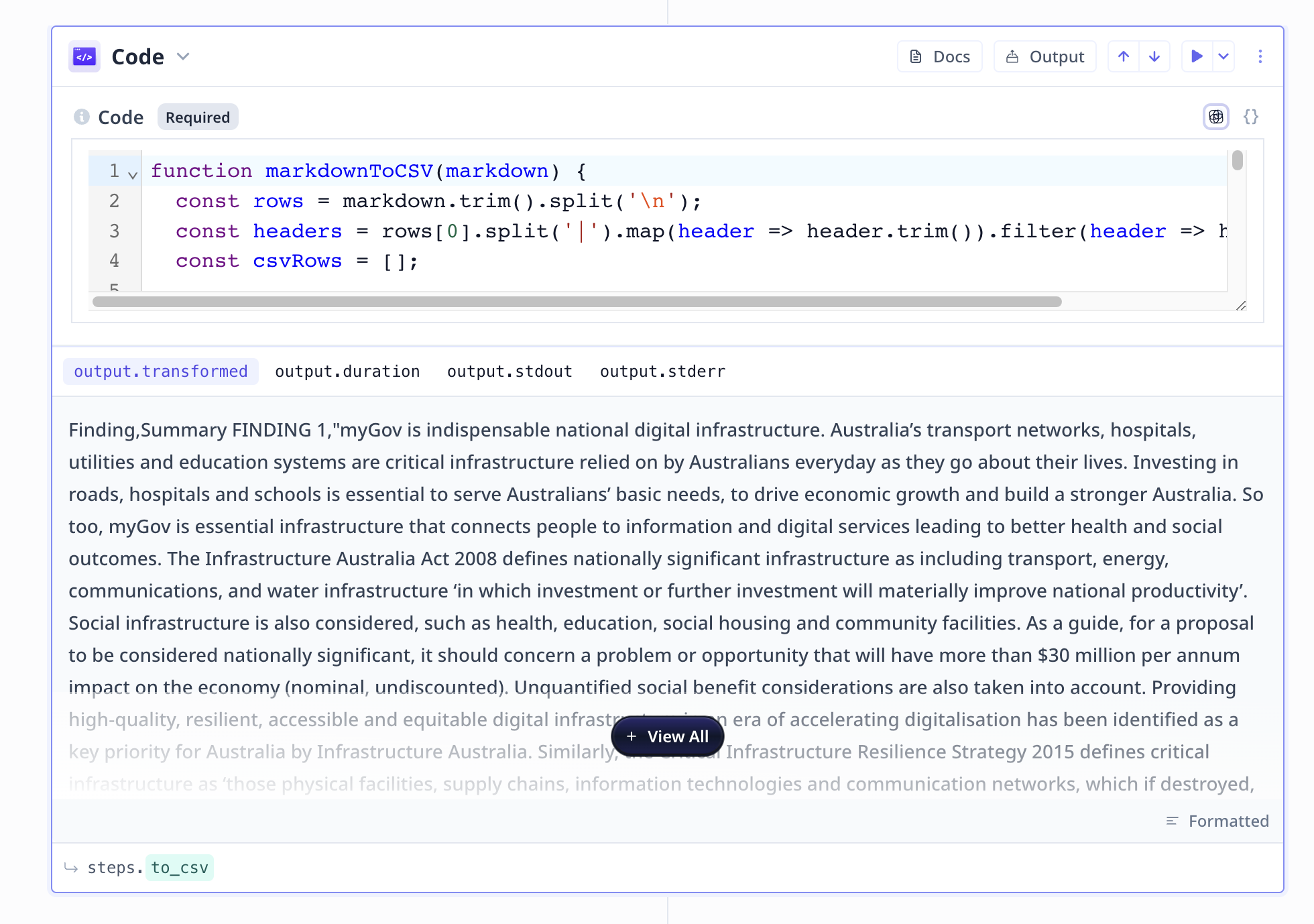 A Javascript code component is available to Run Javascript codes when necessary.
In this Tool, the code-snippet turns the Markdown format to a CSV.
A Javascript code component is available to Run Javascript codes when necessary.
In this Tool, the code-snippet turns the Markdown format to a CSV.
-
A temporary downloadable file
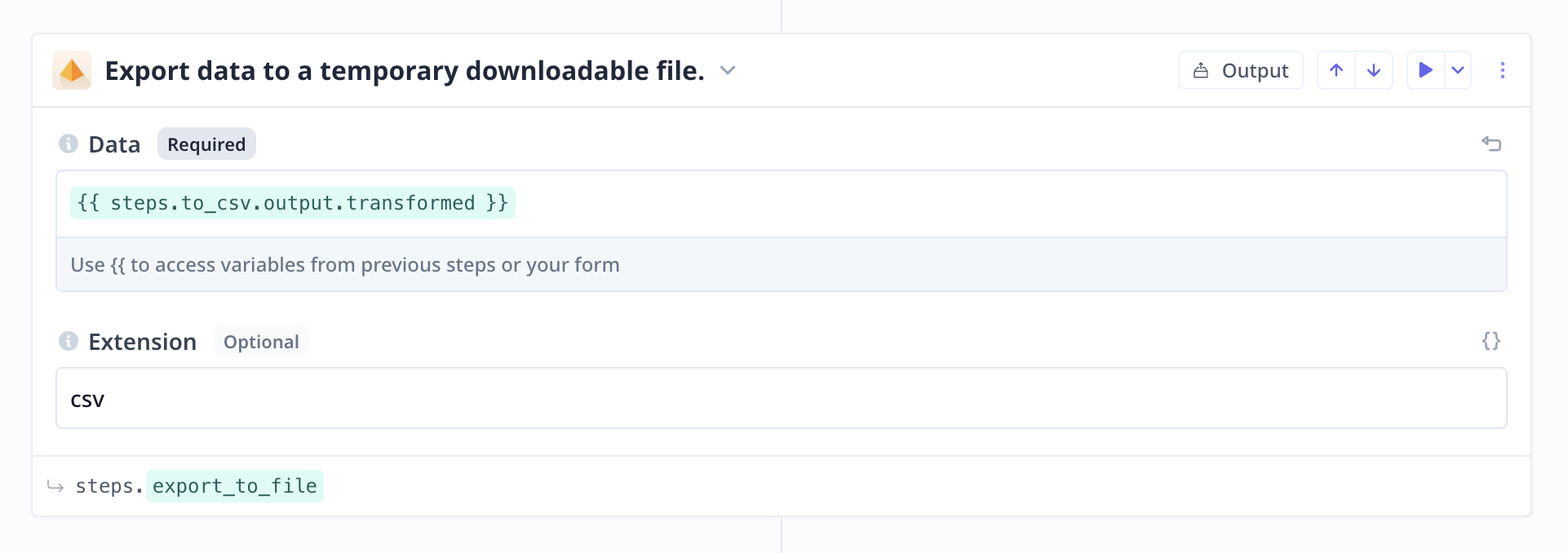 Export to a temporary file:
In many analysis, when the output is generated, it needs to be turned into a downloadable file.
At Relevance this can be easily done via a ready-to-use component.
This component takes some data that is possible to turn into a CSV format, exports the data to
a downloadable CSV and returns a URL to access the file.
Export to a temporary file:
In many analysis, when the output is generated, it needs to be turned into a downloadable file.
At Relevance this can be easily done via a ready-to-use component.
This component takes some data that is possible to turn into a CSV format, exports the data to
a downloadable CSV and returns a URL to access the file.
-
Export to CSV
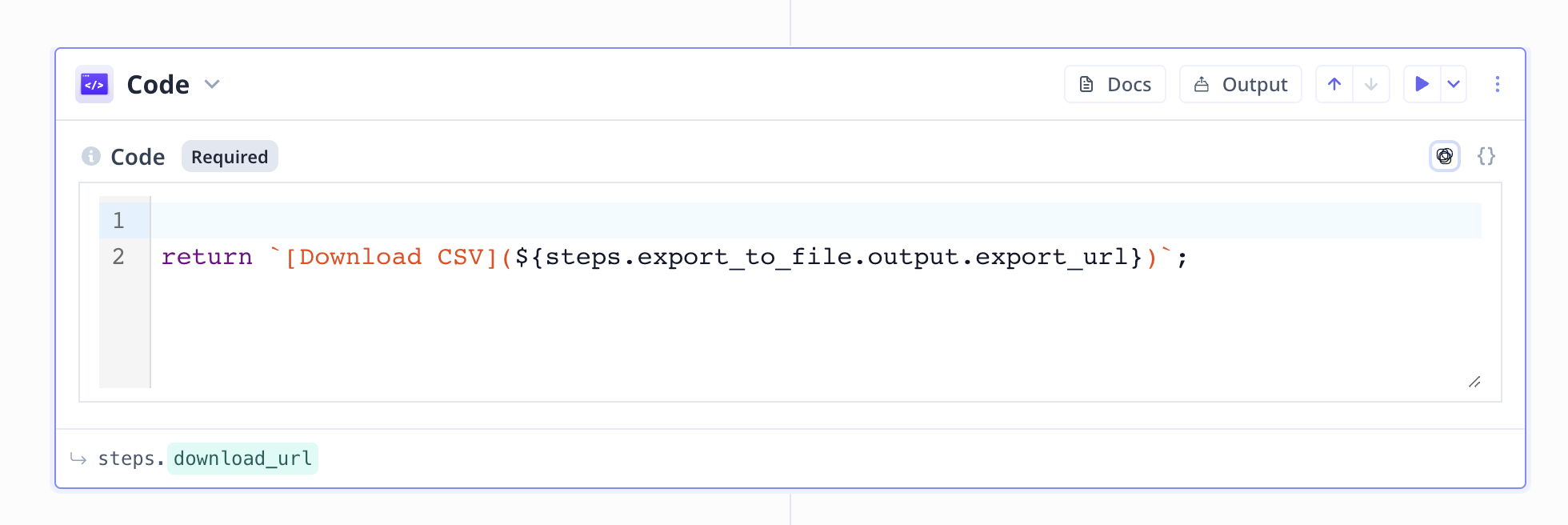 A Javascript code component is available to Run Javascript codes when necessary.
In this Tool, the second code-snippet simply returns the downloadable URL to the output file.
A Javascript code component is available to Run Javascript codes when necessary.
In this Tool, the second code-snippet simply returns the downloadable URL to the output file.