Introduction
Welcome to the documentation for the “Extract Categories in Data” Tool! This Tool is designed to analyze text data and suggest a list of main categories (i.e. themes and topics) seen in the data. Whether you are a data analyst, marketer, or researcher, this Tool will assist you in organizing and understanding your data more effectively. With its advanced AI capabilities and user-friendly interface, this Tool is a game-changer in fast data understanding.Overview
The “Extract Categories in Data” Tool leverages cutting-edge large langue models to analyze text data and extract meaningful categories. It goes beyond simple keyword matching and provides a comprehensive analysis of the data to identify the main themes and topics. By extracting categories, this Tool enables you to gain a deeper understanding of your data and uncover hidden patterns and trends. With its powerful capabilities and intuitive design, it is the perfect solution for understanding unstructured data.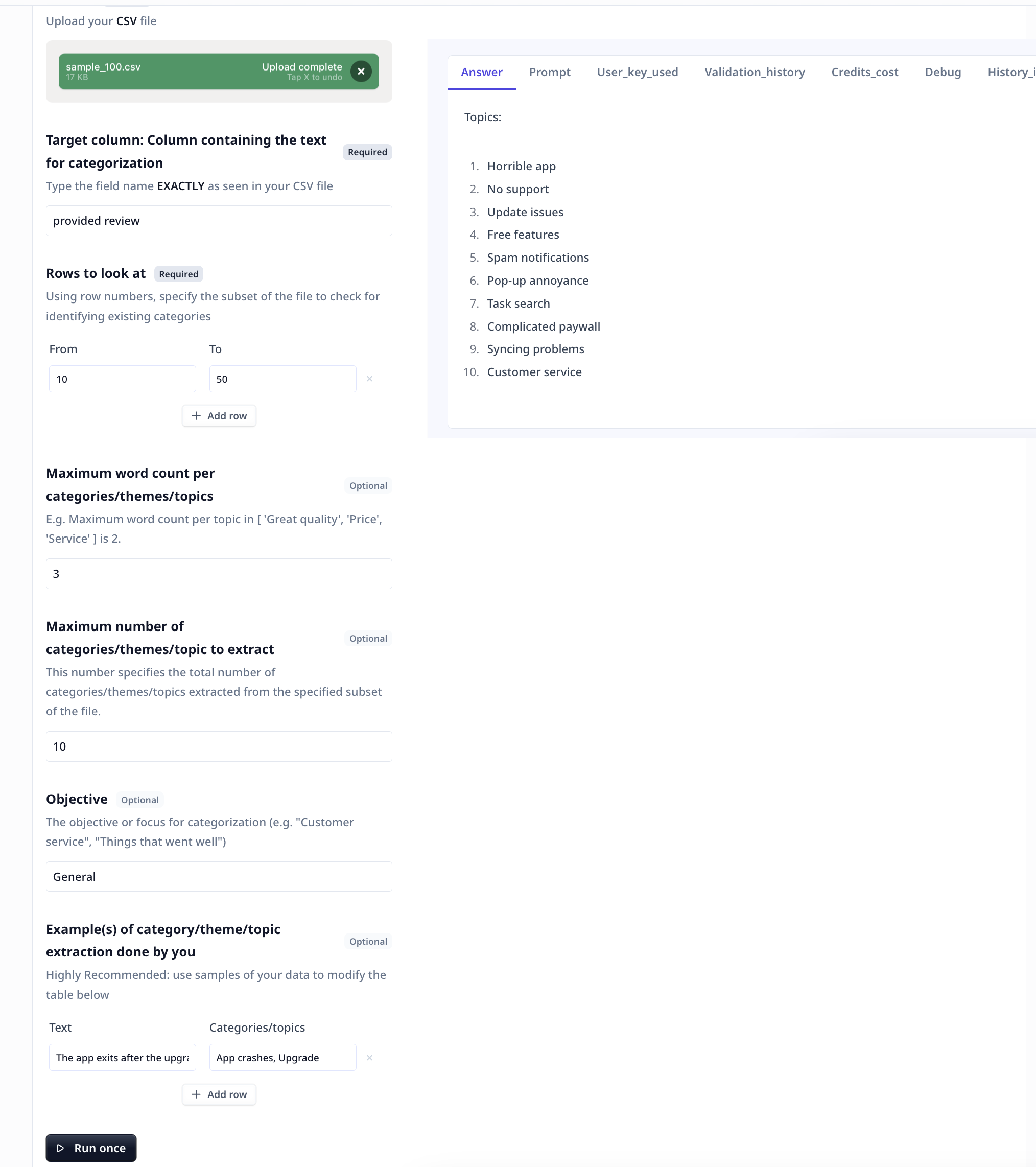
Key Features
- Accurate Categorization: The “Extract Categories in Data” Tool utilizes advanced AI to accurately categorize text data. It analyzes the content and context to identify the main categories and themes. This feature ensures that you receive reliable and accurate categorization results, allowing you to make informed decisions based on the insights gained.
- Customizable Word Count: You have the flexibility to customize the word count for each category or theme. Whether you want a more detailed analysis or a broader overview, you can specify the wordiness of the suggested categories.
- Flexible Taxonomy Count: The Tool allows you to specify the total number of categories or themes to be extracted from the data. Whether you need a few key categories or a more comprehensive taxonomy, you can customize the count accordingly. This flexibility ensures that the extracted categories provide a meaningful representation of your data.
- Objective-Focused Analysis: You can define the objective or focus for categorization, such as “Customer service” or “Product feedback.” By specifying the objective, the Tool directs the LLM model to a certain perspective. This objective-focused analysis enables you to extract categories that are relevant and valuable for your particular use case.
How to use the Tool
Locate the Tool in the template page and click onUse template.
You can use the Tool as is or
clone it.
Follow these steps to extract categories from your text data:
- Upload Data: Upload your CSV file containing the text you wish to understand (e.g. a CSV file of survey responses).
- Specify Field Name: Enter the header of the target column, exactly as it appears in your CSV file. This field contains the text data that you want to analyze.
- Specify what subset to look at: You can specify a subset of the file to be looked at. This is to replicate the data understanding process. No matter how large the number of survey responses are, the discussed topic are more or less the same over the file.
- Customize Word Count (Optional): If desired, you can customize the word count for each category or theme. This allows you to control the wordiness of suggested categories. If left unspecified, the default word count will be used.
- Specify Taxonomy Count (Optional): You can specify the total number of categories or themes to be extracted from the data. This customization allows you to control the breadth of the extracted categories. If left unspecified, the default taxonomy count will be used.
- Define Objective (Optional): If you have a specific objective or focus for categorization, you can define it here. This objective-focused analysis ensures that the extracted categories align with your specific goals. If left unspecified, a general objective will be used.
- Example (Optional): You can provide sample(s) of category extraction done by you. LLMs are proven to work better when they see samples. Provide sample(s) of your text data and the categories you would annotate for the samples.
-
Run the Tool: Once you have uploaded the CSV file and filled the form, click the “Run Tool” button (on the App page) or use
the run options on your data table (bulk/single run) to initiate the categorization process. The Tool will analyze the data and
generate a list of main categories, themes, and topics based on the content and context of the text.
Tool execution at Relevance
Tools and templates can be-
tested on individually provided inputs:
- Single run on the App page
- Single run on the Build page
- Single run on the data table
-
set to fetch the data from a dataset and apply the analysis on the whole dataset:
- Bulk run on the data table
-
tested on individually provided inputs:
- View Results: The Tool will provide you with the extracted categories in a clear and organized format. You can explore the main categories, themes, and topics identified in your data. The results will help you gain a deeper understanding of your text data and uncover valuable insights.
Deep dive in the Tool
Tool components
If you clone a template, or make a Tool from scratch, you will have access to the Build tab. Build is where one put together different components to build a Tool suitable for their needs.User inputs
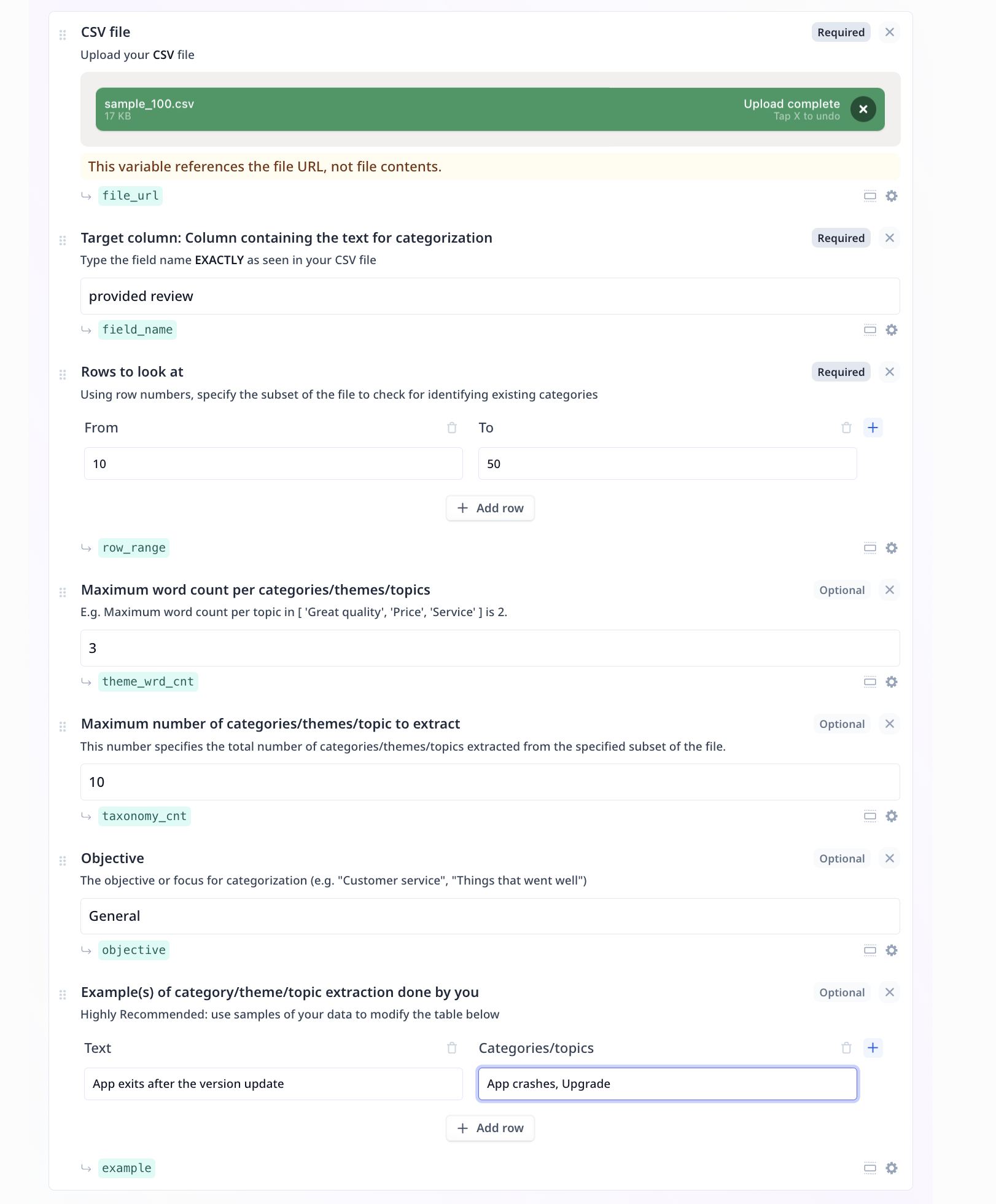
- File to URL: An easy-to-use, one step component, which takes care of all you need when uploading a file for further analysis.
- Text input: An input text component suitable for short text pieces, such as name, topic, a question. This component is used twice in this Tool. Target column and the objective are both of Text inputs.
- Table: A component for entering structured data as input, for instance, rows of samples, each containing fields such as name, last name and age. This component is used twice in this Tool. Row range (from - to) and well as Examples (Text - Categories/topics) are both samples of structured input data.
- Numeric input: An input component suitable for providing numeric values, such as scores, age, maximum or minimum required values. This component is used twice in this Tool. Both maximum word count per category and maximum number of suggested categories are of numeric inputs.
Tool steps
There are 4 components under the Tool steps in this analysis flow. These components take care of three tasks: loading the specified subset of the file, properly formatting the provided samples, and the LLM step.Loading the specified subset of the file
- Loading the file into readable json format
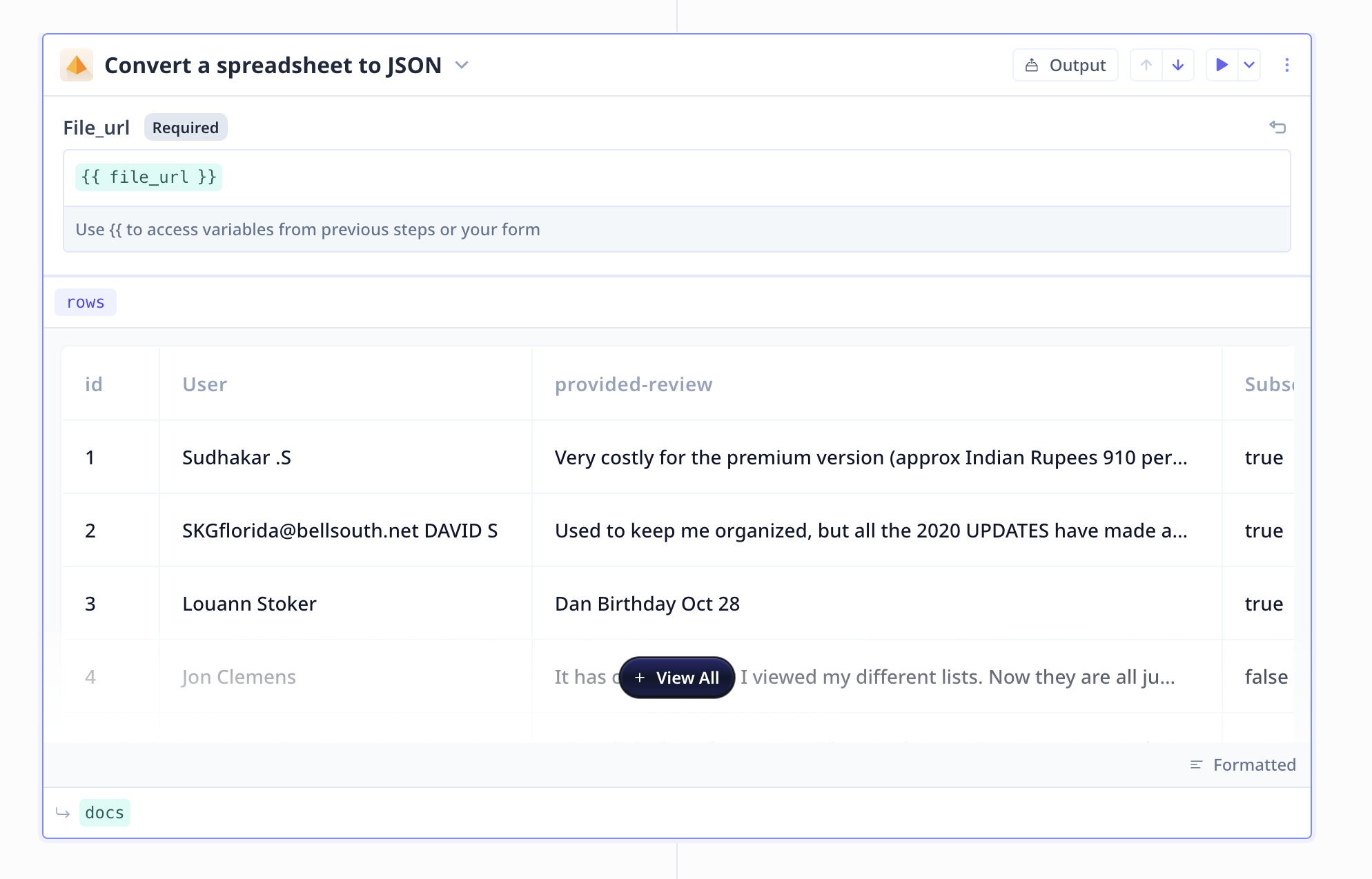
- Selecting the specified subset of the data
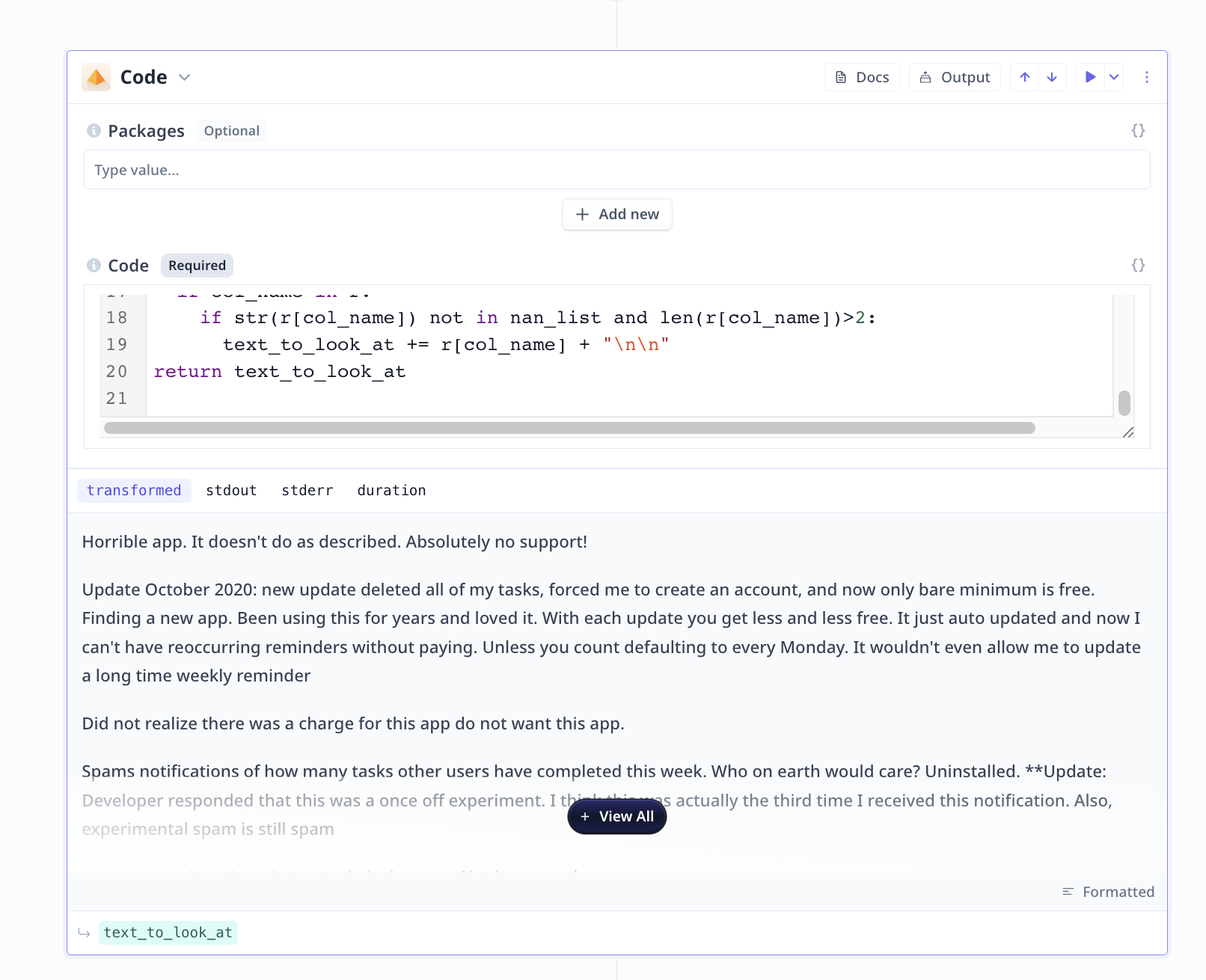
Properly formatting the provided samples
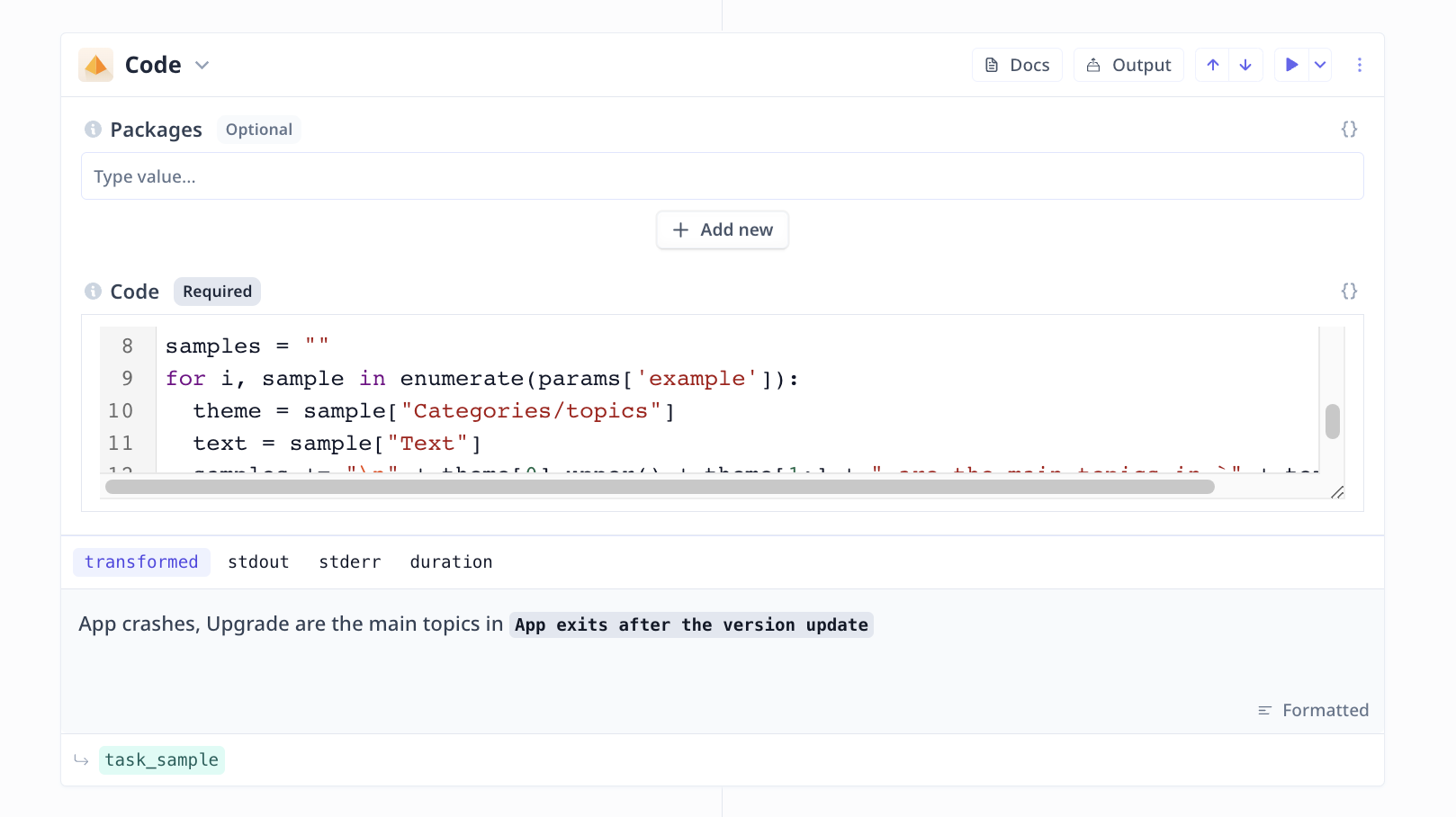
Large Language Model (LLM)
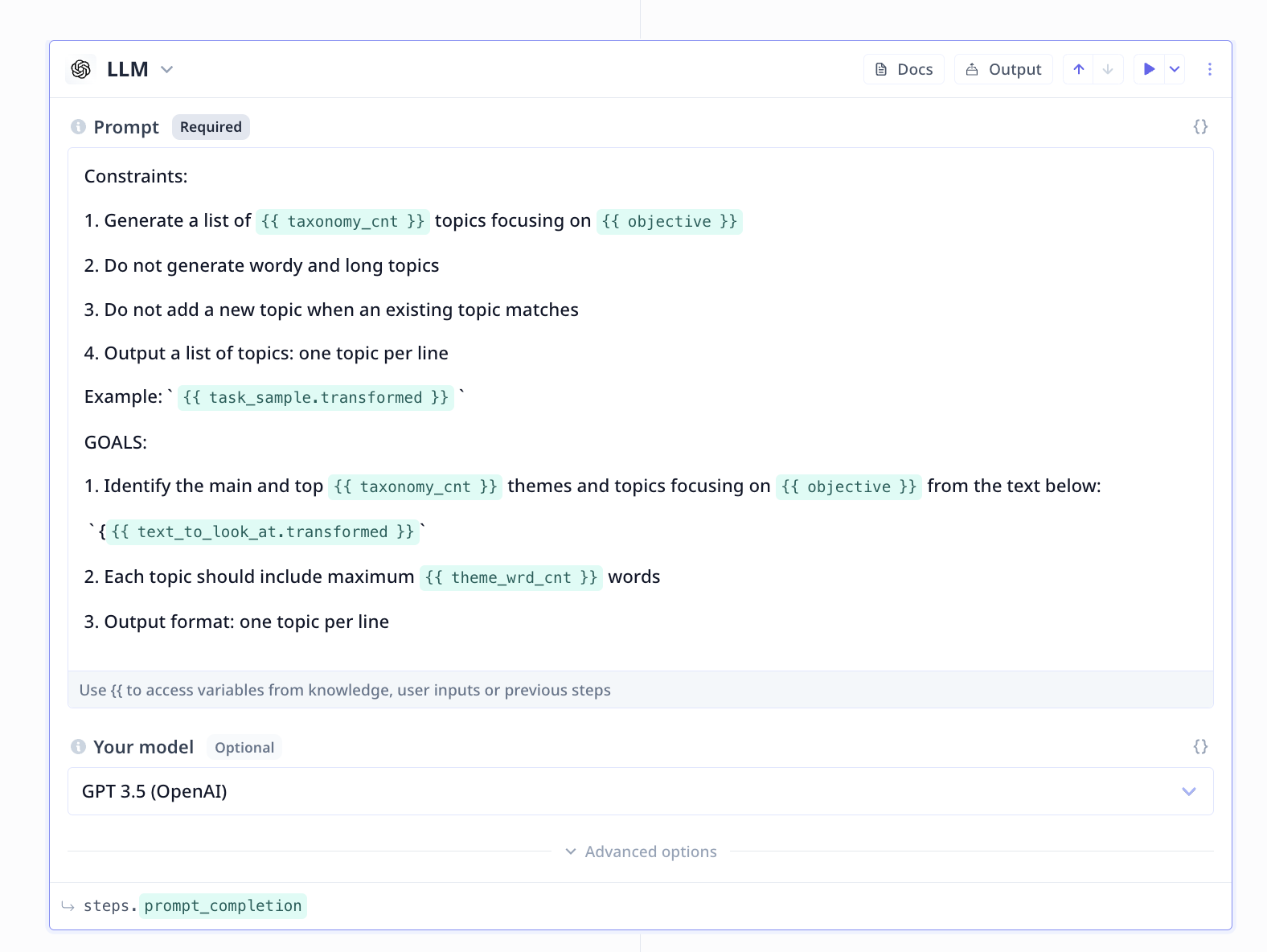
- Be short and precise with your instruction/request from the LLM
- Explicitly note constraints and goals
- Include formatting instruction when necessary