

Ever had that moment when you’re drowning in support tickets, and your team is playing an endless game of ticket ping-pong? Yeah, me too. After spending months building AI-based support systems at scale for customers at Relevance AI, I’ve come to learn that the real game-changer isn’t just using off the shelf LLMs for automation—it’s self-improving automation that actually learns from its mistakes. Let me show you how we approached one such self-improving support system using Agentic Retrieval Augmented Generation (RAG) that reduced response times and increase relevancy of ticket resolution.
The Problem: Support at Scale is Broken
Imagine this: You’re handling 50,000 tickets monthly across multiple products requiring hyper specialized knowledge. Your (human) support agents are juggling between different knowledge bases, Salesforce cases, and email threads. Some tickets need immediate attention, others can wait, and then there are those that keep bouncing between departments because nobody’s quite sure who should handle them.
You are not alone.
The Solution: Enter Agentic RAG
What if we could build a system that not only automates responses but actually gets smarter with every interaction? Here’s how we did it using a two-agent system using Relevance AI platform that leverages advanced RAG techniques.
Meet Our Dynamic Duo
The Support Agent:
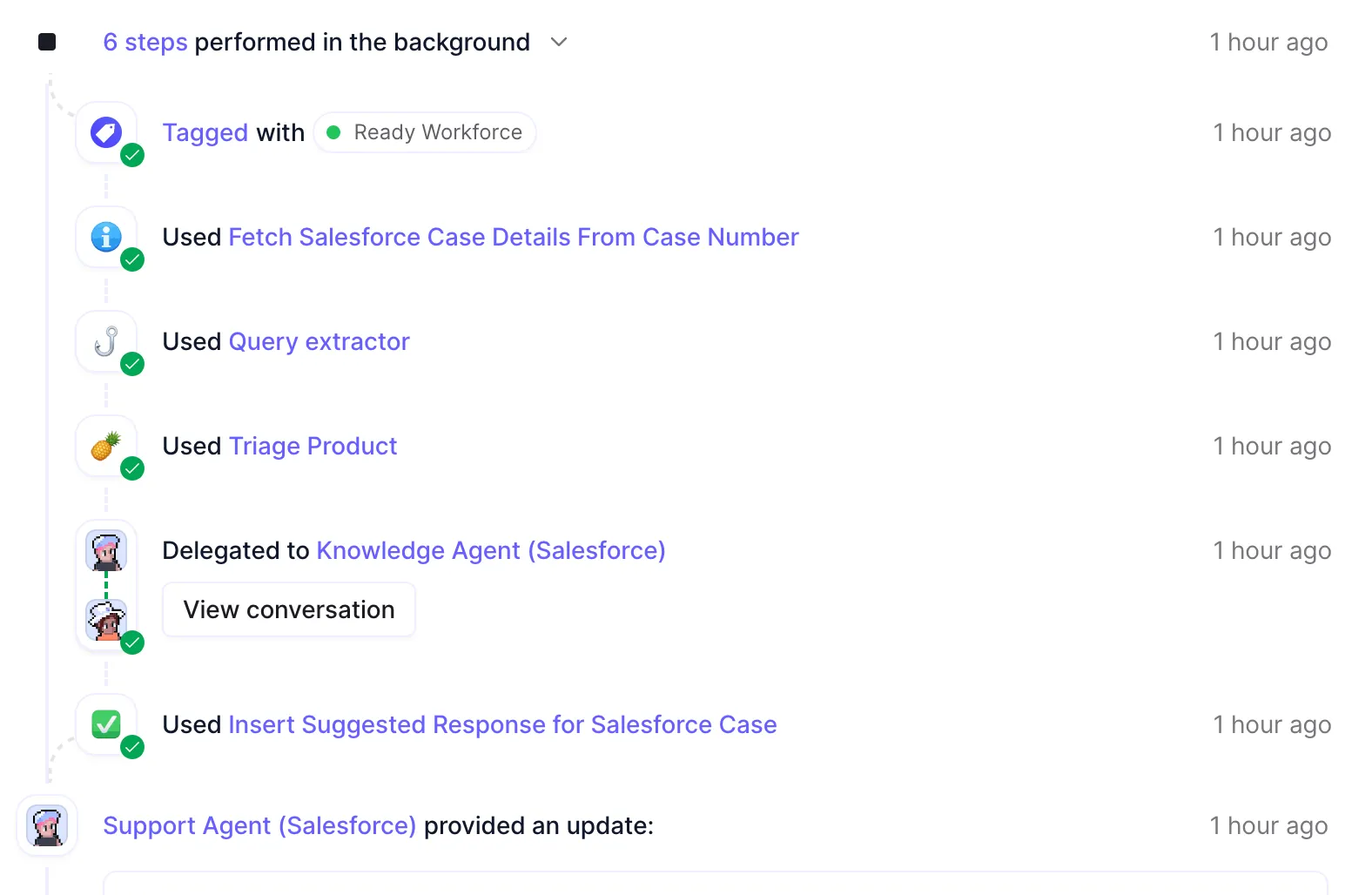
Think of this as your front-desk superhero. This agent handles all the initial heavy lifting:
- Reads incoming tickets from Salesforce and figures out which product they’re about and categorizes into a support category
- Pulls out the important details and extracts multiple queries from those long email threads we all dread including
- Hands over to the Knowledge Agent (below)
- Updates Salesforce with an AI generated response, so the support team can respond immediately
The Knowledge Agent:

This is your behind-the-scenes genius:
- Digs through your knowledge base using advanced RAG
- Has built-in guardrails to prevent those embarrassing AI hallucinations
- Keeps track of what works and what doesn’t
- Turns successful ticket resolutions based on human rating into new knowledge base entries
The Magic: Hybrid Search and Continuous Learning
Here’s where it gets interesting. We combined multiple search approaches to make sure we’re finding the most relevant information:
Advanced RAG with Hybrid Search
We don’t just rely on one type of search. By combining dense embeddings (great for understanding context) with traditional keyword search or sparse embeddings (perfect for catching specific terms), we get the best of both worlds. Think of it like having both a librarian who understands your research topic and a detailed catalog system working together.
Reranking and RRF
Once we find potential matches, we use reranking-based models along with a technique called Reciprocal Rank Fusion (RRF) to combine results from different search methods. It’s like having multiple experts vote on the best answer, with a sophisticated voting system that considers how confident each expert is.
More Techniques
Additionally, we also use:
- Contextual Retrieval: Enriching chunks with more global information to situate them better within the context of each document
- Retrieval post-processing: Leveraging several types of post-processing methods on the retrieved results like summarization, entity extraction, markdown to parse responses for downstream agents
- Citations: Generating inline-citations and grounding the agent’s response in the original verbatim source of information
Never Making the Same Mistake Twice
The real magic happens in how our system learns and improves:
Automated Q&A Generation
Every time a ticket gets resolved successfully, our system automatically creates new knowledge base entries. But here’s the clever part—it doesn’t just copy and paste. It generates multiple variations of the questions, because we all know customers ask the same thing in different ways. E.g. for each resolved entry, we prompt the agent to create three types of Q&A pairs:
- Simple: Can be answered by a single sentence or phrase
- Compound: Requires complex answers with spread out context
- Conditional: Requires a specific condition to be met
Human in the Loop
When support team rates, or improve an automated response, the system doesn’t just update that one answer. It:
- Updates the knowledge base with the correction
- Generates new question variations based on how the customer actually asked it
- Adjusts its confidence thresholds for similar cases in the future
What Makes This Different: Smart Guardrails
We built several layers of protection to ensure quality:
References
Each answers is always backed by the reference to the historical ticket or article URL that is used by the agent to formulate a response, so the support team can verify as well as dig for more information should they need to.
Confidence Thresholds
The system knows when it’s not sure and will always route complex or uncertain cases to human agents, noting the limits of its knowledge, instead of speculating or hallucinating a response. It’s like having a junior agent who knows exactly when to ask for help.
Product-Specific Validation
Each product line has its own knowledge base and set of rules and validations. The system won’t suggest a solution for Product A if it’s only valid for Product B.
Building Your Own System
Want to implement something similar on our platform? Here are the key steps:
- Start Small: Begin with a well-structured knowledge base for one product line
- Layer Your Search: Implement basic RAG, then add hybrid search capabilities
- Build Your Feedback Loop: Set up systems to capture and integrate human feedback early on
- Add Guardrails: Start with basic validation rules and expand based on what you learn
- Run Evals: Continuously run evaluations on both synthetic data and historical tickets to track performance over time
- Monitor and Adjust: Keep a close eye on agent metrics, time to resolution, and human feedback
What’s Next?
We’re currently exploring:
- Multi-modal support for images attachments
- Predictive routing based on historical patterns
- Better document parsing and extraction with Vision Language Models (VLMs)
- Custom metadata extraction like sentiment analysis for proactive escalation
- Improved telemetry and observability into agent’s behaviour and performance
Conclusion
Building an agentic RAG system for support isn’t just about implementing the latest LLM techniques. It’s about creating a system that learns, adapts, and most importantly, knows its limitations. The key is to start small, focus on high-impact areas, and continuously iterate based on real feedback.
Remember, the goal isn’t to replace human support agents entirely – it’s to make them more efficient by handling the routine stuff automatically and giving them better tools for complex cases.


