

Retrieval Augmented Generation (RAG) is the application of information retrieval techniques to generative models, such as Large Language Models (LLMs), to produce relevant and grounded responses, conditioned on some external dataset or knowledge base.
In layman terms, RAG enables generative models to source answers quickly and accurately from large data-sets. We firmly believe that an AI agent, like a team-mate, is only as good as the training and knowledge-sharing it receives. As such, having a world-class RAG implementation is key to our vision of enabling every business to employ an AI Agent one day.
Some key challenges with LLMs that are addressed by RAG are:
- Hallucinations
- Adaptability, or lack of expert knowledge (e.g. internal company documentation)
- Limited information due to knowledge cut-off
However, it is not a silver bullet and requires careful consideration in terms of its components and architecture. For example, it is sensitive to things like:
- Quality of embeddings
- Base LLM model for response generation
- Parsing strategy
- Chunking strategies (recursive, window, child-to-parent, hierarchical, semantic)
- Lost in the Middle issues where context/information from the middle is lost
- Retrieval strategies (vector-based or dense, keyword-based or sparse, and hybrid)
Furthermore, there is a need for rigorous evaluation to ensure factuality and grounding in the provided data sources.
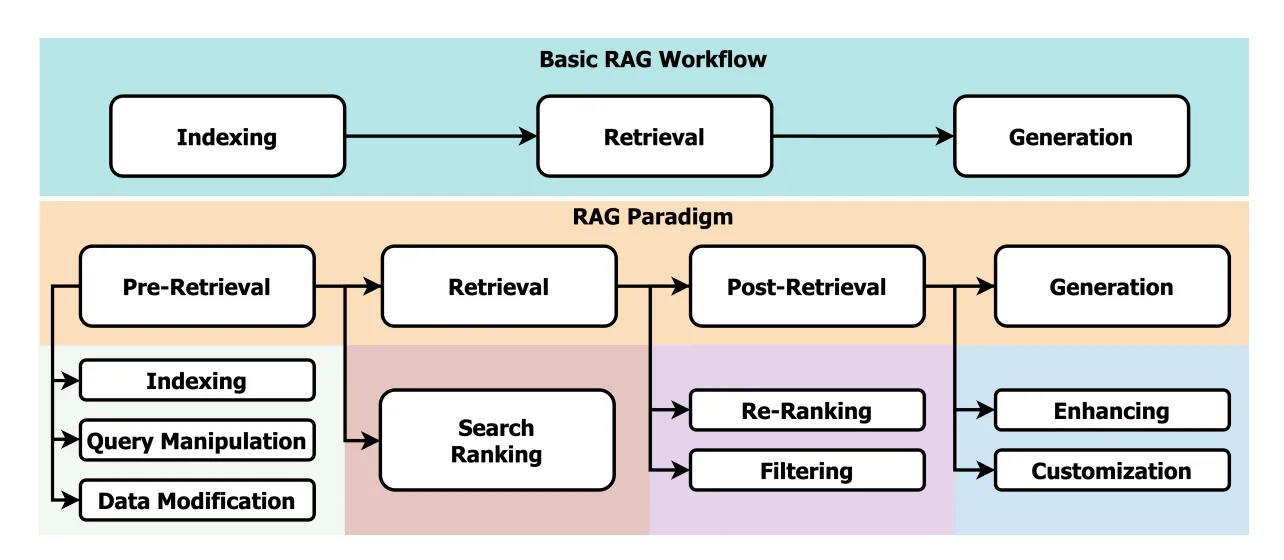 Fig 1. Naive and advanced RAG paradigms [1]
Fig 1. Naive and advanced RAG paradigms [1]
Improving our RAG Architecture
When I joined Relevance AI, the first major task was to improve our existing RAG system—to make it accurate, easier to iterate, more auditable, and future-proof it, to a degree.
Key Hypotheses
To break down the task into achievable goals I developed 5 key hypotheses.
- Reduce hallucinations down to under ≤ 5% with advanced RAG
- Create novel hierarchical and metadata-aware document parser using vision models
- Create agent-based router with document taxonomy for fine-grained RAG
- Create a better synthetic data generation pipeline
- Identify optimal hyper-parameters for chunking, retrieval, reranking and generation stages based on rigorous metrics
Formulation
RAG generates an output sequence Y = (y1, y2, ..., yM) token-by-token given an input sequence X = (x1, x2, ..., xN) and a set of retrieved documents D = (d1, d2, ..., dK).
The probability of generating Y is calculated as:
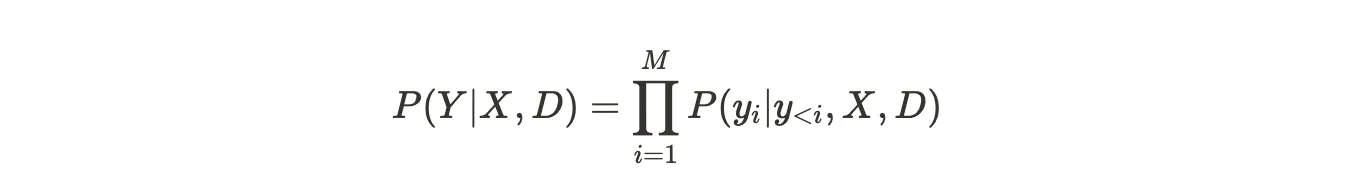
Where y_{<i} = (y_1, y_2, ..., y_{i-1}) are the previously generated tokens.
The conditional probability is modeled by the following:
- Encode input
Xinto contextual representations using an encoder. This is typically an embedding model:H = Encoder(X) - Encode all documents
Dinto document representations: **C = Encoder(D)** - Retrieve relevant documents
D ⊆ Dbased onXandCusing a retriever:D = Retriever(H, C) - Pass the retrieved document
Dto the generator to generate each token
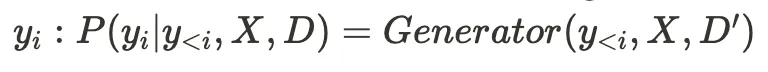
Some key components:
- Encoder: Dense embedding model to get contextual representations
- Retriever: Dense passage retrieval, sparse, or hybrid
- Document Encoder: Same encoder used for input or separate for efficiency
- Generator: Autoregressive language model conditioned on input and retrieved documents
Additionally, techniques like query manipulation, retrieval reranking, retrieved document selection, enhancing and customization can improve performance.
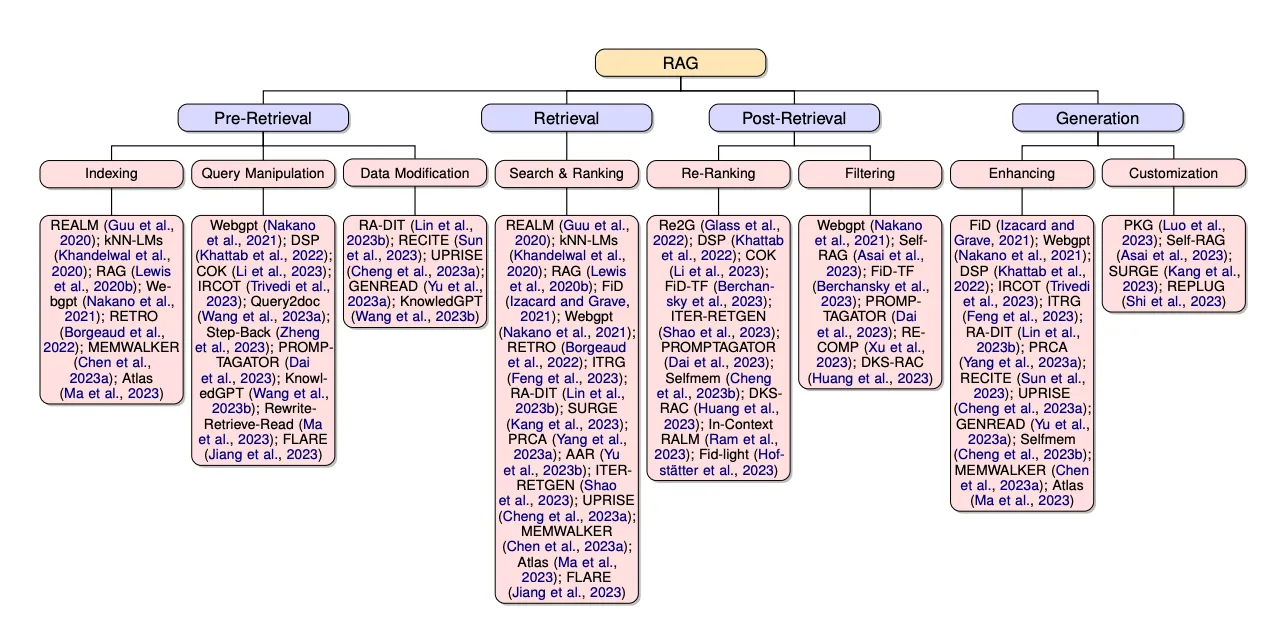 Fig 2. Current state of RAG [1]
Fig 2. Current state of RAG [1]
Metrics
We evaluate the retrieval and generation stages of our RAG pipeline separately using the metrics discussed below.
Note: We use the following terms interchangeably: contexts ↔ ground truth chunks (unless specified as retrieved) ↔ top-k chunks ↔ number of retrieved chunks.
Retrieval
- Mean reciprocal rank (MRR): Measures the rank of the highest-placed relevant chunk for a given query.
- Hit Rate: Measures the fraction of queries where the correct response is found within the top-k retrieved chunks
- Contextual Precision: Evaluates the retriever by measuring if chunks in the retrieved context that are relevant to the query are ranked higher proportional to the irrelevant ones.
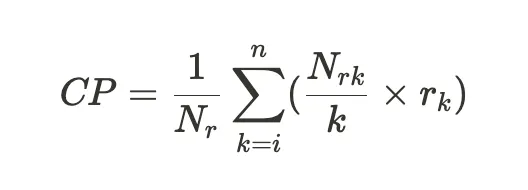
where k is the (i+1)th chunk, Nr is the number of relevant chunks retrieved, Nrk is the number of relevant chunks up to k, and rk is a binary indicator for chunks that are relevant vs not.
- Contextual Recall: Measure the extent to which retrieved chunks (contexts) aligns with the ground truth answer.
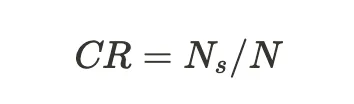
where N8 is the number of attributable statements as extracted and classified by the evaluator LLM, and N is the total number of statements.
- Contextual Relevancy: Measures the relevance of information in the retrieved context for a given query. Similar to answer relevancy below but the evaluator extracts statements from the retrieved context instead of the response.
Generation
- Answer Relevancy: Answers how relevant the actual output of your LLM application is compared to the provided query.
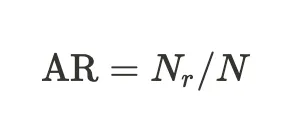
where N is the total number of statements and Nr is the number of relevant statements. A LLM is used for extracting the statements from the response, and then classifying whether those statements are relevant to the query.
- Faithfulness: Measures whether the response is factually aligned with the retrieved chunks/contexts. It is given by:
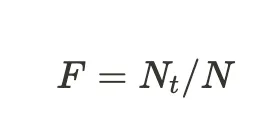
where Nt is the number of truthful claim and N is the total number of claims. The evaluator extracts all claims made in the response and then classifies which are truthful based on the facts in the retrieved context.
- Hallucination: Measures the degree of factual correctness by comparing the response to the ground truth context.
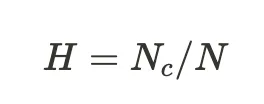
where Nc is the number of contradicted contexts and N is the total number of ground truth chunks or contexts.
Implementation Details
Synthetic Data Generation
Dataset for RAG
In order to accurately assess the performance, I needed to create synthetic test datasets which closely model the real world data generation process. For a RAG system, this comes down to creating a dataset of which contain the gold labels:
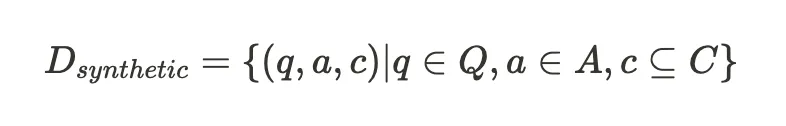
where (q, a, c) represent a single test example triple of query, answer (or ground truth) and contexts respectively. Query is the user question, ground truth is the factual or expected response from the system and contexts are the verbatim references in the text.
The are many frameworks that allow for synthetic dataset generation like llama index, RAGAS and deepeval and come with their own set of parameters.
However, as we’ll discuss below, these approaches often require pre-chunked text and hence the quality of the test set becomes highly dependent on the method of chunking. This also raises another fundamental issue as to how humans parse a document and might think to ask questions. They are usually not all co-located within a single arbitrary chunk but rather relates to a more flexible, conceptual understanding of the document where the derived contexts may or may not be co-located.
Pipeline for synthetic corpus creation
We propose using vision as the modality of choice for generating a test set.
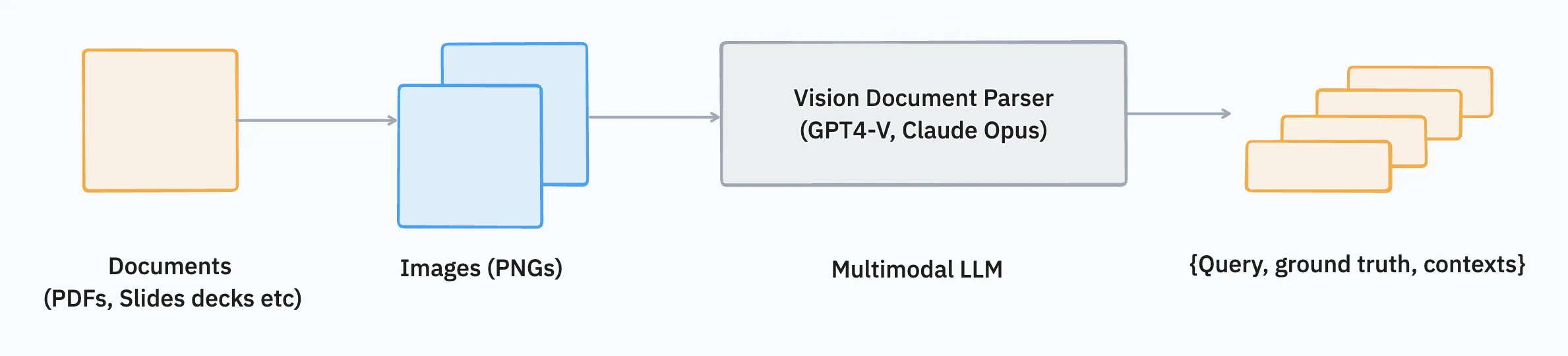
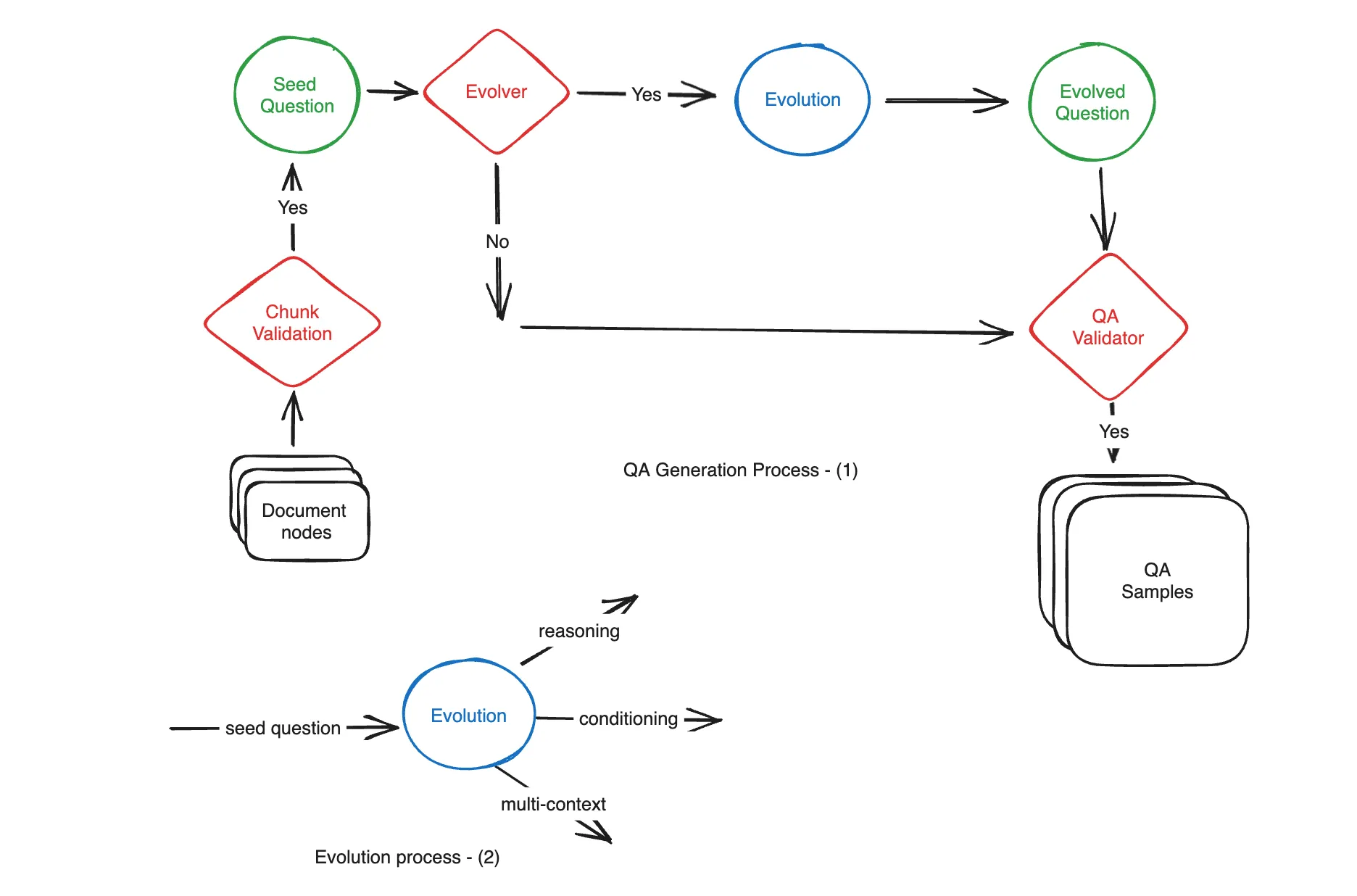
Steps:
- Ingestion: For documents with rich media and text that have non-trivial structures, we extract the contents as an image
i is a member of Ikwherekis the total number of pages or slides, for example. - Prompting: We select a multi-modal LLM (like GPT4-V) to process the images next. Here we use function calling and provide strict prompts around grounding the Q&A pairs (with regex assertions) in factual/verbatim references from the source image. The derived output, along with the
(q, a, c)triplet, also contain other metadata like difficulty level, whether the question requires multi-step reasoning etc. for a more downstream granular assessment. - Post-filtering: We apply various techniques like similarity thresholding to determine a smaller set
IcfromIkand filter out redundant samples from the final set. Thereafter we randomly sample 5% of the test set for human validation to ensure it meets our internal criteria. - Enrichment: Optionally, we also apply an evolutionary paradigm inspired by Evol-instruct using the RAGAS framework on the base set to generate variations that capture dimensions like reasoning and conditioning. Multi-context is captured in step (2).
Ingestion
Parser
During ingestion, the initial stage is for effective information extraction from various document types and formats. Extracting text and images varies quite a lot between each of these formats given their often incompatible and non-interoperable native encodings and standards. Broadly,
- We use standard file readers that support .docx, .jpg, .png, .jpeg, .mp3, .mp4, .csv, .epub, .md, .mbox and .ipynb
- For .pdf and .pptx we propose a different methodology, using the agent router technique below, due to its inherent structure
Initiatives like llama parse and directory reader from llama index (which is a high-level abstraction for file readers like PyMuPDF etc) seek to address this. However, document types like in the latter category are often sub-optimal as the relative structure between different components were not preserved thus making retrieval poor. Naive PDF readers would often break the hierarchy while extracting text, for example:
Customer Data Focus Product Data Focus Strengths Strengths Feedback-driven development Privacy first Fast iteration cycles Rapid prototyping ..
In the next section, we address this shortcoming with an agentic framework.
Agent-based router
I started by first defining a taxonomy of document types and their formats. Below is a rough overview of this taxonomy.
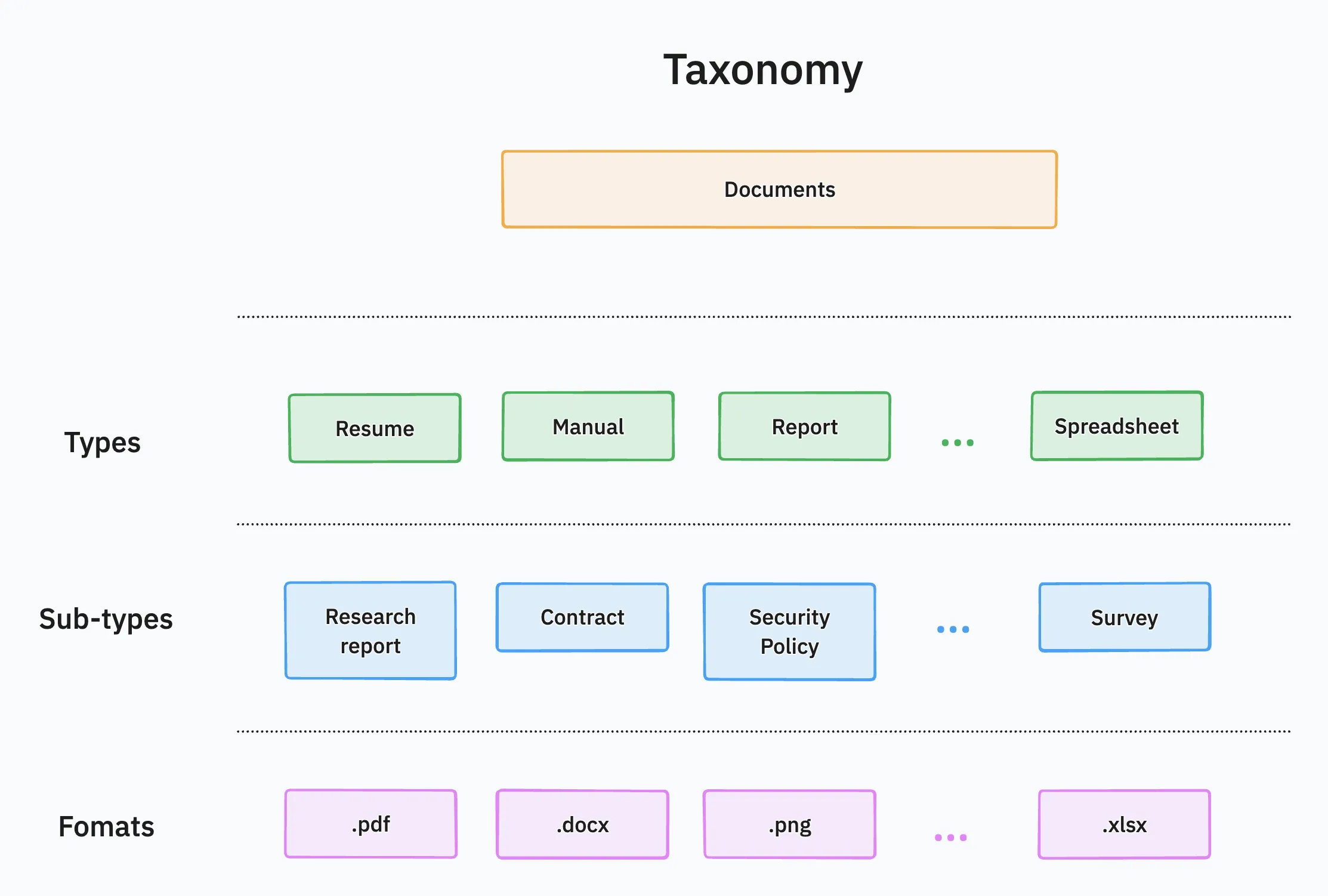
In this two-fold framework, the agent first:
- Classifies the document type (and sub-type) from a flexible schema
- Use the document type, sub-type and format to determine the best parsing method
- For .pdf and .pptx, this would be re-using the vision LLM for text extraction and outputting a structured markdown. Using the same example above we now get:
## Customer Data Focus ### Strengths - Feedback-driven development - Privacy first # Product Data Focus ## Strengths - Fast iteration cycles - Rapid prototyping ..
Similar to the synthetic data creation pipeline, we use a multimodal LLM as the classifier by feeding the first p \leq P pages, where P is the total number of pages (p = 3 by default).
The pipeline is document agnostic and further allows the user to “route” the query through different RAG strategies that best fit a document type/sub-type as determined through a grid search.
Embedding
Based on the Massive Text Embedding Benchmark (MTEB) [2] with an optimal balance between size and performance, we select the state-of-the-art BGE-family of open-source models published by BAAI [3]. Their smaller model bge-small-en-v1.5 (with 384 dimensions and 512 sequence length) in particular has high throughput and runs well even on low to mid-end consumer hardware. For asynchronous tasks with agentic loops, we switch to the larger bge-large-en-v1.5 (with 1024 dimensions and 512 sequence length).
Additionally for closed source, we go with: OpenAI’s text-embedding-3-large , Cohere’s cohere embed-english-v3.0 which rank highly in benchmarks.
On the closed source front we observe text-embedding-3-large consistently outperforming other proprietary models. We report the results in the sections below.
Indexing
For indexing and storing vectors, we leverage Qdrant DB. Their HNSW indexing algorithm provides robust performance for approximate nearest neighbour (ANN) searches with extremely low latency.
Chunking
We adopt the following strategies for chunking:
- Base (default): Splitting based on a fixed chunk length. Several experiments have noted 1024 to be the optimal chunk size that balances the signal to noise ratio within a context window
- Window: Keeping a $M$ sized window over a given number of chunks. This allows the retriever to reference chunks or nodes that appear together within a sliding window
- Child to parent: Allows for retrieval of a smaller chunk that references a larger parent chunk. This is especially effective when the subject of our query is located in a smaller region but requires the surrounding context to actually answer the same. Has overlapping advantages with the window approach
- Semantic: The final approach we using an LLM to determine the “context boundaries” in the text that are related and have high semantic cohesion to then tokenize on the same
Retrieval
For our retrieval strategy, we use the following:
- Vector: Dense retrieval based on semantic similarity
- Keyword: Sparse retrieval based on keyword-based BM25 algorithm
- Hybrid (default): Use both vector and keyword based approaches to return a most relevant chunks
Reranker
Post-retrieval reranking allows for the chunks to be essentially reordered using a different model trained to compute relevance given some query and search results (chunks in our case). We try the following:
- Cohere reranker v2 and v3 (closed source)
- BAAI flag reranker (open source)
Generation
Finally, we choose the following LLMs to be the response generator using the retrieved chunks to answer the given query:
- GPT 3.5 and 4 turbo
- Mistral Large and Medium
Key Results
Preliminary experiments: Basic RAG
Hyper-parameter Optimization
In order to determine the best combination of embedding, chunking and retrieval strategies, we perform a grid search over the following hyper-parameters:
- Chunking:
- Base: Uses a basic sentence splitter for chunking along with additional sanitization and cleaning
- Embeddings:
- OpenAI’s
text-embedding-3-large - Cohere’s
embed-english-v3.0
- OpenAI’s
- Retrieval:
- Vector search
- Keyword search (BM25 or Best matching algorithm)
- Hybrid (keyword + Vector search)
- Generation:
- OpenAI’s
gpt-3.5-turboandgpt-4-turbo-preview - Mistral’s
mistral-medium
- OpenAI’s
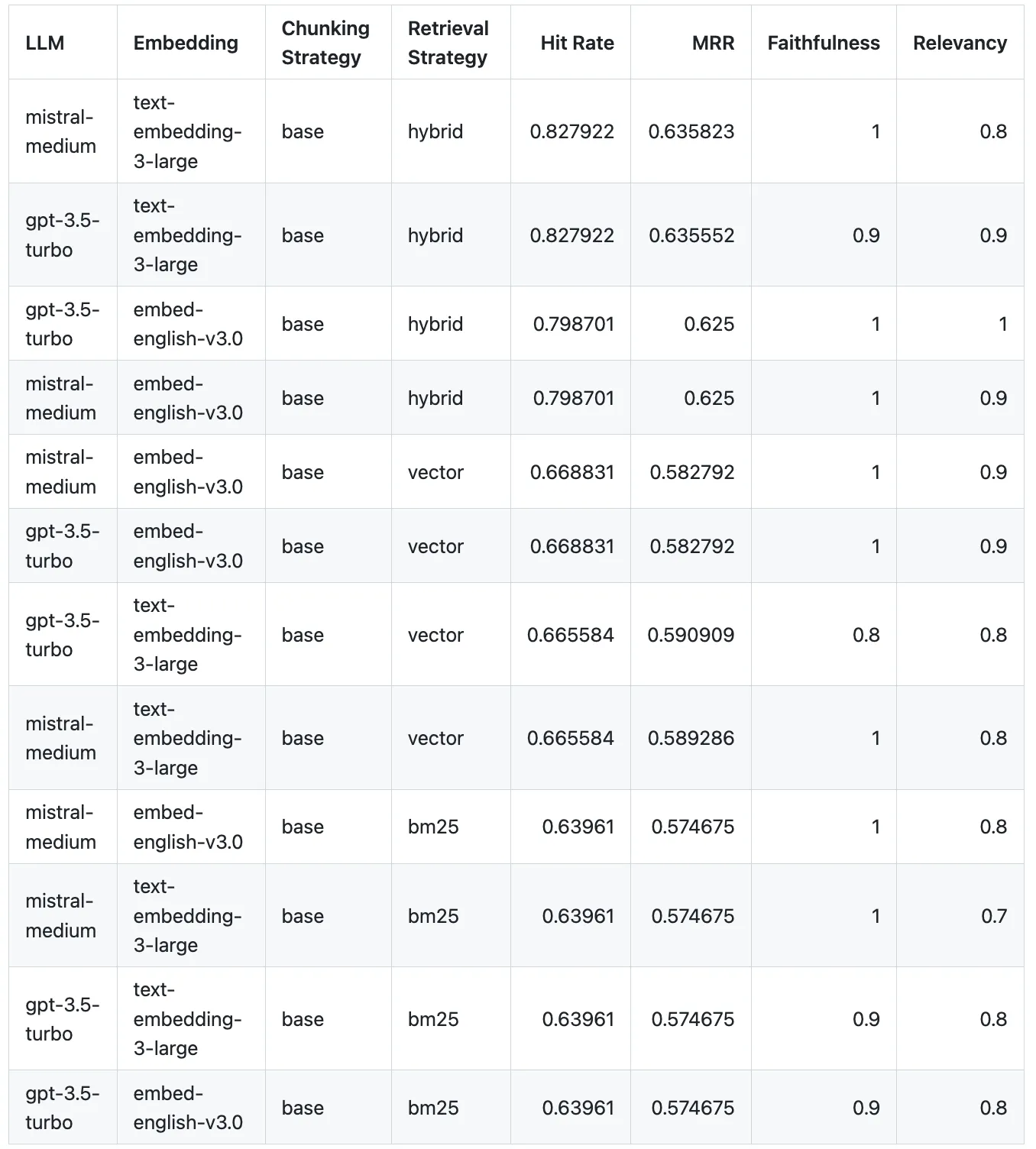
Below are some of the results using the closed sourced (highest performing) models:
Observations
- When it comes to overall performance, including metrics for both retrieval and response, Mistral’s
mistral-mediumwith OpenAI’stext-embedding-3-largeusing a hybrid approach (BM25 with vector search) performs the best. Using the same hybrid approach and embeddings but with GPT-3.5-turbo as the LLM, it comes as second best. - Mistral medium on the whole is more faithful as compared to GPT-3.5-turbo. However, only one combination i.e.
gpt-3.5-turbowith Cohere’sembed-english-v3.0, using hybrid retrieval, scored perfectly on both faithfulness and relevancy. - For retrieval strategies, the hybrid approach consistently outperforms the other two approaches.
- Keyword-based traditional strategies unsurprisingly perform the worst. However, they tend to augment vector-based methods and improve performance overall as per (3).
Note: For this experiment we do not use the reranking step to get a baseline performance.
Legacy vs Advanced RAG v1.0
Next up, we measure performance, especially hallucination rates, between our legacy system vs advanced RAG on a synthetic dataset.
The legacy retrieval had the following specifications:
- Chunking: Fixed length tokenization with a max sequence length of
64 - Embedding:
all-mpnet-base-v2 - Retriever: Vector search on KNN vector data type via MongoDB Atlas
- Generator:
gpt-4-turbo
For advanced retrieval:
- Chunking: Recursive base tokenizer
- Embedding:
bge-small-en-v1.5 - Retriever: Hybrid (vector + BM25)
- Reranker:
rerank-english-v3.0 - Generator:
gpt-4-turbo
Observations
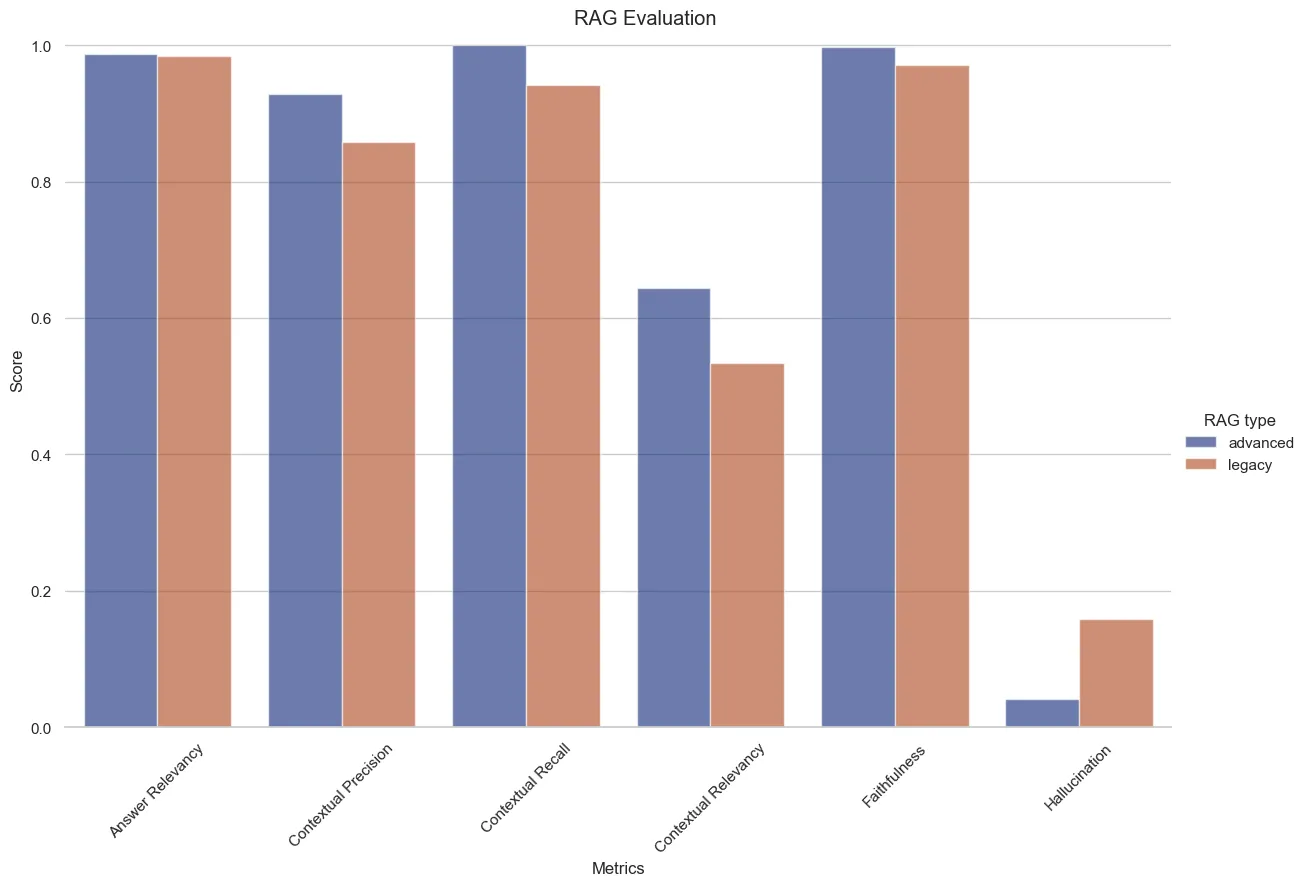
- Advanced RAG performs better across the board
- Reduction in hallucination from
~16%to about4% - We get near perfect scores on contextual recall and faithfulness
- Contextual relevancy is also up from
53%to64%. This can be pushed even further with window or child-to-parent chunking which should increase the signal-to-noise ratio (SNR) - Contextual precision and recall are also much better
Note: Larger score is better for all metrics except hallucination; measured @k=3

Enabling the AI Workforce
It worked! Our Advanced RAG system is better on every measure than our legacy RAG system.
Expect this to improve over time as we continue to iterate on it going forward. It’s now enabled for all Relevance AI customers. Sign up now and try it out!
Learnings
Some reflections on what worked and what did not.
- Currently, GenAI adoption suffers from what can be colloquially termed as the “last mile problem” of AI. The first 95% (setting up a RAG system, getting 80-90% accuracy etc.) is fairly achievable. However, the final 5% (≤ 1% hallucination in production, handling out-of-distribution cases and more) requires a disproportionate amount of work and research relative of the other 95%.
- RAG can help alleviate a lot of the issues when dealing with internal / proprietary data but requires careful evaluation. This often comes down to synthetic data generation based on customer data for building trust in the pipeline.
- Documents with inherent structures, such as resumes, require more careful consideration. Using naive extraction methods lead to abrupt breakages in content with shared context. They require special vision-based LLM parsers to output text in format like markdown, while preserving the hierarchy and structure.
- Using LLMs to evaluate LLMs comes with caveats, given evaluator / judge LLM may also suffer from hallucination, arbitrarily. For evaluation on the retrieval component, using classic information retrieval metrics like hit rates, mean reciprocal rank (MRR), precision and recall is more rigorous.
References
- A Survey on Retrieval-Augmented Text Generation for Large Language Models
- MTEB leaderboard
- BAAI models
- Llama Index
- Deepeval
- RAGAS
- Evol Instruct
- Qdrant DB
