

The AI agents landscape has exploded [1] in the last year or so. With many different platforms, frameworks, models available to choose from, we are all spoilt for choice.
Internally, at RelevanceAI as well - we have a large AI workforce, which consists of agents, and each agent has access to tools/functions. We are provider agnostic and allow our users to use from a wider variety of models and share multiple agent templates [2] as well.
Introduction to Agents and the changing landscape
But, first - what really is an AI agent? What are tools?
At the time of writing, there is much confusion in the community on how to clearly define agents [3].
The technology is new, possibilities are endless, and we are only just starting to scratch the surface with AI agents. We have not yet landed on a clear definition of agents as a whole, but, to give the reader some context:
Agents were popularised by OpenAI’s function calling announcement back in June 2023 [4], see snippet of announcement below:
Developers can now describe functions to gpt-4-0613 and gpt-3.5-turbo-0613, and have the model intelligently choose to output a JSON object containing arguments to call those functions. This is a new way to more reliably connect GPT’s capabilities with external tools and APIs.
This ability to be able to call tools or “act” on behalf of the user, is what describes an “agent”.
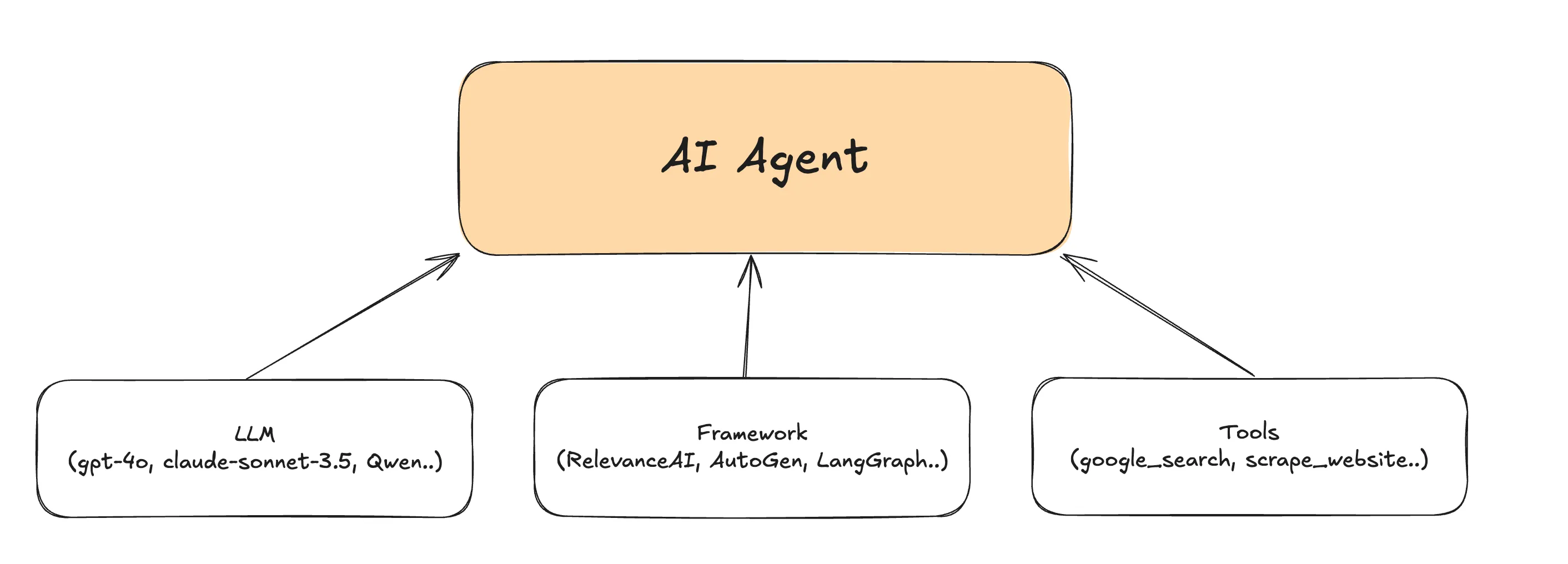
The one definition that resonates the most with our understanding is one from agent arena [5], that describes an agent as consisting of three components - LLM models, framework and tools!
Agents are defined as entities that can perform complex tasks by leveraging various subcomponents. We define each agent to be made up to three components - LLM models, tools, and frameworks.
Some examples of each of these three components are:
Frameworks: RelevanceAI, LangGraph, LlamaIndex, PydanticAI
LLM models: Claude, GPT-4, LLaMA3.2
Tools: Google search, Twitter API, LinkedIn API
And fundamentally, the performance of an Agent will depend on all three (this aligns well with our internal benchmarking and experimentation):
- A weaker LLM might have lower performance due to argument parsing compared to a larger LLM
- For all agents, their superpowers will come from their tools! Providing access to the right tools allows agents to perform their tasks better and therefore, increasing their performance and end result.
- No/low-code frameworks like RelevanceAI really reduce the barrier to entry, and act as the binding agent to a delicious recipe for success! Your framework of choice will also depend on your requirements.
State of AI Agents today
Agents are to be seen everywhere today. Since the last year, their usage has skyrocketed [6].
In the words of Andrew Ng [7],
What’s the one most important AI technology to pay attention to? I would say agentic AI.
In fact, in this YouTube video [8], Jared Friedman, the managing director of YCombinator believes that they are going to be $300 billion plus companies started in vertical AI Agent space!
Today, we also see multiple companies utilising agents to automate most of their internal workflows - BDR agents [9], research assistants, coding assistants, robotic arms [10] and more [11]!
Agents are being used very widely - both by technical and non-technical teams.
But, at the same time - while their usage is increasing, fewer companies are monitoring their attention in production. There is also uncertainty around these agents. They sometimes call the wrong tools, despite properly crafted system prompts. Closed source APIs are a blackbox, and we do not completely understand their inner workings. Open source LLMs on the other hand are catching up very quickly [12].
The field is moving fast with new releases on a daily basis, and, as builders - we must take responsibility of all agents that we build. This means:
- Having a deep understanding of the datasets, model and workflow that AI agent would be deployed in.
- Building a rigorous evaluation suite for all agents
- Monitoring agent performance in production and safeguarding it from jailbreaks!
All three tasks are time consuming, but, extremely important for success.
As part of this blog post, we will dig deeper into building and testing production quality agents.
Build responsibly
To harness the full power of AI agents, we need to be good prompters. We need go beyond “vibe checks” [13] and add more science to our thought process.
There are multiple good resources on prompt engineering available today:
Initially, it was hard to see how prompt engineering will shape as a field, but today, we all stand corrected - we need to be good prompters to build high performing agents. That means having clearly defined goals for agents. As builders, we cannot be vague in our system prompt. Clarity is what leads to success.
To quote some good examples on writing high quality system prompts, see - Anthropic’s prompt generator [17], Claude’s system prompts [18] and gpt-4o [19].
All three have one thing in common - they are clearly defined, well structured, and give direction to the agent.
To build a production grade agent, these are some of the must haves:
- Agent must be reliable (calls the right tools based on input)
- Agent must be reproducible (produces same or similar output given the same input)
- Agent must not hallucinate (does not make up facts)
- Agent must escalate to human when in doubt
Having a human in the loop is essential. This acts as a safeguard when agent doesn’t know what to do. Inside the relevance platform, we can set tools to be in “approval mode” - this means an agent asks a human for permission before executing on the tool. We also have in built tools such as “escalate to human” which allows the agent to ping a human in case the agent is confused.
And taking responsibility also means having rigorous evals setup for all your agents. Evals are the differentiator between building agents for a hobby and enterprise ones that get used by big corporations.
With that being said, let me share our philosophy on Evals at RelevanceAI.
Introduction to agent evaluation
At Relevance AI, we measure all our agent success on two broad metrics:
- Quantity: measures the quality of agent output based on requirements shared by user.
- Quality: measures the percentage of conversations marked as successful based on a predefined metric.
Evalagent = (Scorequantity, Scorequality)
The definitions of these metrics change per agent. But, overall, these are the parameters we judge our agents on:
- What is the % of conversations for which the agent “successfully” does what it’s asked to do?
- Is the information shared by the agent to the user of high quality? If not, what’s missing?
Each quantity and quality metric is normalised to have a value between 0-1. This means, in our monitoring dashboards, an agent builder could simply look at the agent’s performance in production, and say “performance for Agent X has reduced by 20% in the last three months in terms of quality.”
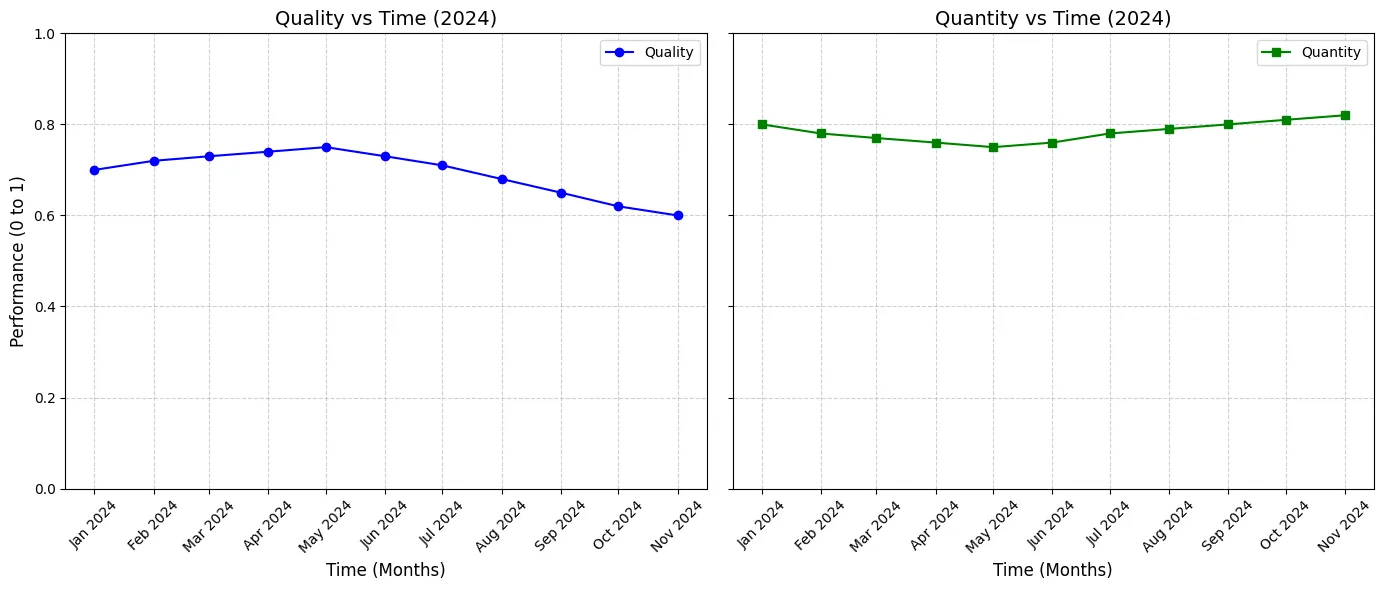
Having each metric between 0-1 also allows us to have internal dashboards such as the one shared in image above.
This provides clear information to our agent builders, that for the particular agent in question, while the quantity metric is going up, the quality of outputs is going down. Thus, the call to action could be:
- Use a specialised and fine-tuned LLM for the agent
- Update system prompt
- Change base model
By having custom metrics on quality and quantity - and moving away from usually defined metrics such as rouge, fluency, consistency - we have developed an internal framework that works for “all” our agents and helps build more reliable metrics.
We will be further sharing more resources to talk more in depth about how we have built these quality and quantity metrics for agents in the upcoming blog posts. And how you can build such metrics too!
To learn more about the platform and help you build agents quicker - refer to the Relevance AI academy [20]! Thank you for reading.
