

Semantic LLM Cache
Reduce latency and spend when working with LLMs
Chain template name
Categorize and label your data without any human bias Categorize and label your data

Relevance AI
🔥 Popular
Chain template name
Categorize and label your data without any human bias Categorize and label your data
Relevance AI
🔥 Popular
Customer name
Categorize and label your data without any human bias Categorize and label your data
Relevance AI
Customer name
Categorize and label your data without any human bias Categorize and label your data
Relevance AI
Customer name
Categorize and label your data without any human bias Categorize and label your data
Relevance AI
Customer name
Categorize and label your data without any human bias Categorize and label your data
Relevance AI

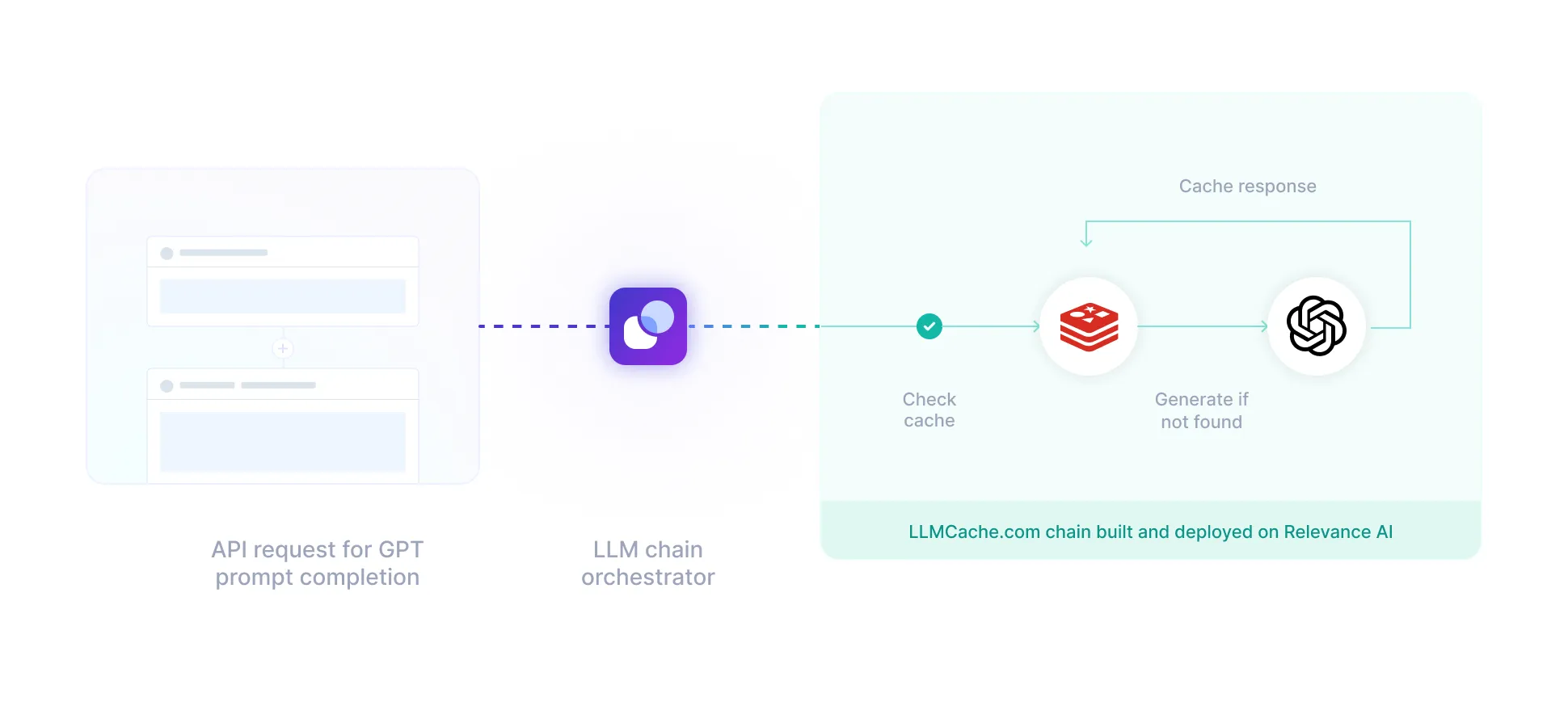
Partnered with Redis
Relevance AI partnered with Redis. Stronger and faster than ever.
Key features
Optimised LLM cache for your AI
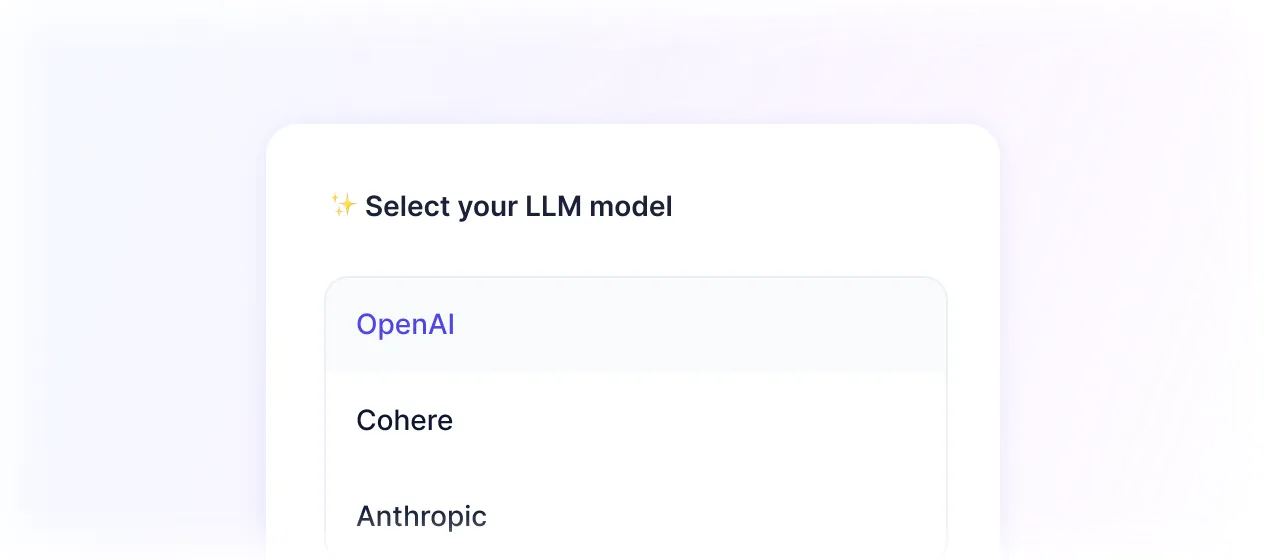
Works out of the box with multiple LLMs
Works out of the box with LLMs with OpenAI, Cohere, Anthropic and more.

Multiple LLMs embeddings
Cache using Cohere, OpenAI, Huggingface and SentenceTransformers embeddings.

Reduce cost
Don't pay for the same prompt twice.
Millisecond caching latency
Speed up your LLM load times.

Crucial caching features supported
Crucial caching features such as TTL, Replication and more.
Enterprise grade security
Secure by default with industry best practices and fine-grained access controls, SSO support and private-cloud deployments.
SOC 2 Type 2 certified
GDPR compliant
Automated compliance checks
Annual 3rd-party penetration tests

SOC 2 Type 2 certified
GDPR compliant
Automated compliance checks
Third-party penetration tests




