
Data Transformation Rules AI Agents
Understanding AI-Powered Data Transformation Rules
Data transformation rules are the logic patterns that convert raw data from one format to another, making it useful for analysis and operations. When powered by AI Agents, these rules become dynamic, self-learning systems that can understand context, adapt to changes, and maintain data quality at scale. Unlike traditional static rule sets, AI-powered transformation rules evolve based on new data patterns and user feedback.
Key Features of Data Transformation Rules
- Natural language processing capabilities for intuitive rule creation
- Dynamic schema mapping and automatic format detection
- Self-learning algorithms that improve transformation accuracy over time
- Real-time validation and error correction
- Automated documentation and version control
- Intelligent handling of edge cases and exceptions

Benefits of AI Agents for Data Transformation
What would have been used before AI Agents?
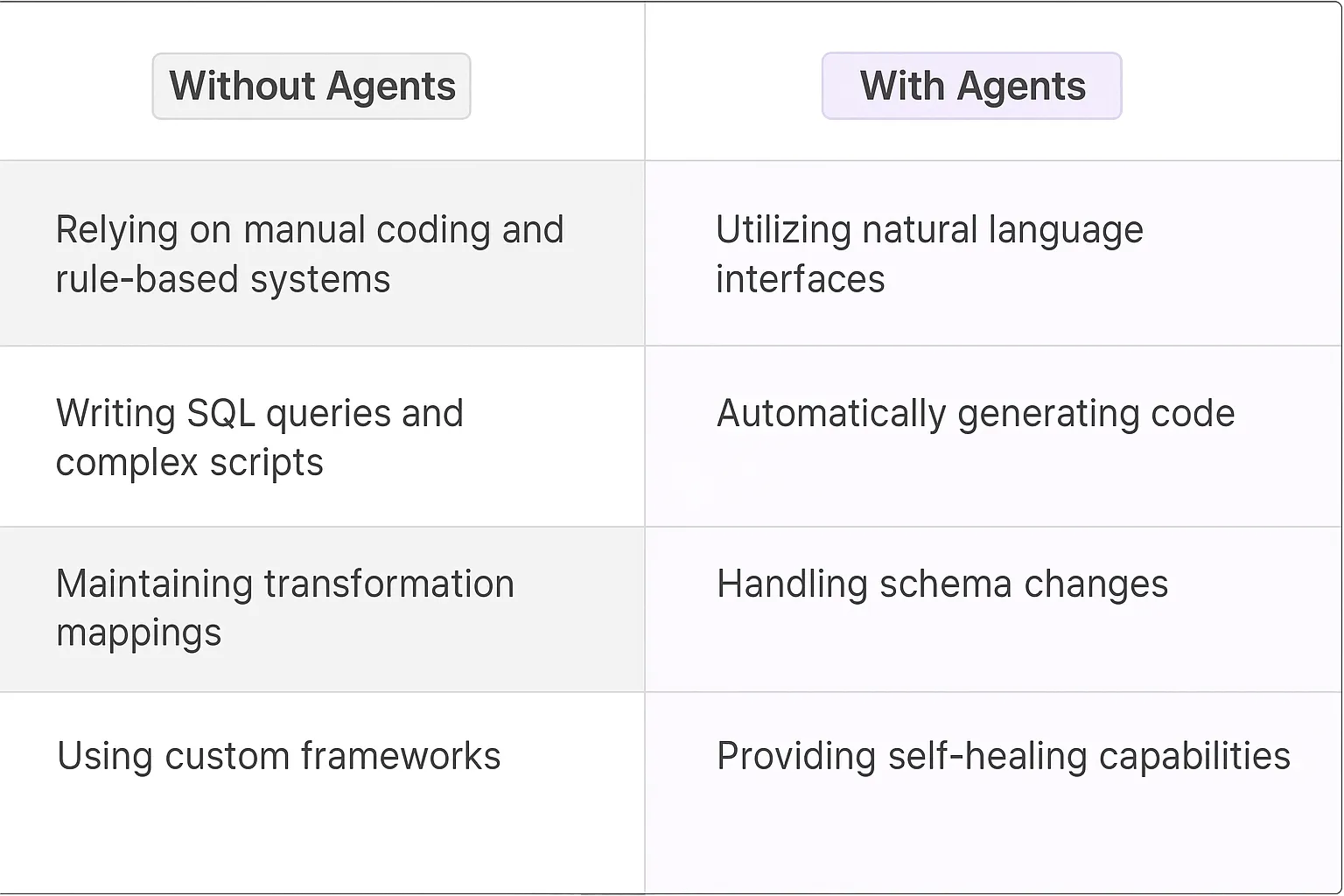
Traditional data transformation relied heavily on manual coding and rule-based systems. Engineers spent countless hours writing complex SQL queries, ETL scripts, and data mapping logic. They'd maintain massive documentation of transformation rules, debug edge cases, and constantly update mappings as data schemas evolved. The cognitive load was intense - one small error could cascade through the entire data pipeline.
Teams often cobbled together a mix of Python scripts, Apache Airflow DAGs, and custom frameworks. When business requirements changed, it meant diving back into the code, updating multiple dependencies, and extensive testing cycles. The technical debt accumulated quickly.
What are the benefits of AI Agents?
AI Agents fundamentally shift how we handle data transformation by bringing intelligence and adaptability to the process. These digital teammates can understand natural language descriptions of transformation requirements and automatically generate the necessary code and rules.
The network effects are particularly compelling - as more teams use AI Agents for data transformation, the systems learn from each successful implementation, becoming increasingly sophisticated at handling edge cases and complex scenarios. This creates a powerful flywheel effect.
Key advantages include:
- Natural language interfaces that allow business analysts to define transformation rules without deep technical knowledge
- Automatic detection and handling of schema changes and data drift
- Self-healing capabilities that can identify and correct transformation errors
- Built-in data quality validation that catches issues before they impact downstream systems
- Version control and documentation that's automatically generated and maintained
The most interesting aspect is how AI Agents reduce the cognitive load on engineering teams. Rather than maintaining complex transformation logic, engineers can focus on higher-value tasks like architecture and optimization. It's a classic example of technology augmenting human capabilities rather than replacing them.
Potential Use Cases of AI Agents with Data Transformation Rules
Processes
- Converting raw customer data from multiple sources into a standardized format for CRM integration
- Transforming legacy database structures into modern schema formats
- Normalizing international date and currency formats across global datasets
- Cleaning and standardizing address data from various input sources
- Converting XML documents to JSON format for API compatibility
Tasks
- Automatically detecting and fixing data inconsistencies in real-time
- Creating custom validation rules for specific data types
- Mapping fields between different database systems
- Generating transformation documentation and audit trails
- Building reusable data cleaning templates
The Growth Loop of Data Transformation
Data transformation is the hidden engine powering modern software companies. When I talk to founders building the next generation of data tools, I'm seeing a clear pattern emerge: the companies that win are the ones that nail the intersection of automation and human insight.
The most effective data transformation agents operate on what I call the "transform-learn-improve" loop. They start by handling basic transformations, learn from human corrections, and continuously refine their rule sets. This creates a powerful flywheel effect where each transformation makes the system smarter.
Key Benefits
- Reduced manual data cleaning time by up to 80%
- Consistent data quality across all business units
- Faster time-to-insight for analytics teams
- Scalable data governance and compliance
- Enhanced data reliability for machine learning models
The companies seeing the most success with data transformation agents are those that treat them as integral parts of their data infrastructure, not just bolt-on tools. They're building entire workflows around these digital teammates, creating new possibilities for data-driven decision making.

Industry Use Cases
Data transformation rules represent one of those deep technical challenges that historically required specialized engineering teams and complex ETL processes. AI agents are fundamentally changing this paradigm across industries in fascinating ways. The ability to intelligently parse, clean, and restructure data opens up entirely new possibilities for organizations to extract value from their information assets.
What's particularly compelling is how these digital teammates can adapt to industry-specific data formats and compliance requirements. They're essentially becoming domain experts that understand the nuances of different data structures while maintaining governance standards - something that previously required significant human oversight and specialized knowledge.
The real power emerges when we look at how different sectors are leveraging these capabilities. From healthcare providers normalizing patient records across disparate systems to financial institutions standardizing transaction data from multiple sources, AI agents are handling complex data transformation tasks that once required extensive manual intervention.
This shift represents more than just automation - it's a fundamental change in how organizations can approach their data transformation challenges, with AI agents serving as intelligent partners that understand both the technical and business context of the data they're processing.
Healthcare Data Standardization: From Chaos to Clarity
The healthcare industry drowns in data fragmentation. Every hospital, clinic, and lab operates like its own data island - using different formats, nomenclature, and structures for essentially the same information. A Data Transformation Rules AI Agent acts as the universal translator in this complex ecosystem.
Take Memorial Regional Hospital's radiology department (anonymized example). Their radiologists were spending 2-3 hours daily just reformatting reports from partner clinics. Lab results came in using different units of measurement, diagnostic codes varied between facilities, and patient history data lived in incompatible formats.
The Data Transformation Rules AI Agent learned the specific data patterns and requirements from thousands of historical records. It now automatically:
- Converts measurement units (mg/dL to mmol/L)
- Standardizes diagnostic codes across different classification systems
- Restructures free-text clinical notes into structured data fields
- Maps varying terminology to a unified medical vocabulary
The real magic happens in the edge cases. When the AI encounters a new variation - like a novel abbreviation or unconventional data format - it flags it for human review while continuing to process the standard transformations. This creates a continuous learning loop where the system gets smarter with each iteration.
The impact? Radiologists now spend those saved hours on patient care instead of data formatting. More importantly, the standardized data enables better analytics, faster research, and improved patient outcomes through consistent information sharing across the healthcare network.
This isn't just about efficiency - it's about creating a foundation for better healthcare delivery through clean, consistent, and reliable data transformation flows.
Financial Services: Taming the Multi-Source Data Beast
I've spent time with dozens of fintech companies, and they all face the same thorny problem: reconciling financial data from a maze of sources. Banks, payment processors, trading platforms - each speaks its own distinct language. The complexity compounds when you're dealing with cross-border transactions and multiple currencies.
A mid-sized investment firm I advised (let's call them Capital Dynamics) was drowning in this exact challenge. Their analysts wasted 4+ hours daily wrestling with data from 15 different financial feeds. Each source had its own quirks - Bloomberg terminals spitting out one format, Reuters another, and internal systems adding yet another layer of complexity.
Their Data Transformation Rules AI Agent now handles these intricate conversions by:
- Normalizing currency pairs and exchange rates across time zones
- Converting proprietary trading codes into standardized identifiers
- Harmonizing timestamp formats from global markets
- Restructuring unstructured news feeds into quantifiable data points
The fascinating part is how the AI adapts to market evolution. When new financial instruments emerge or regulations change reporting requirements, the system detects these patterns and suggests new transformation rules. It's like having a data scientist who works 24/7 and never misses a beat.
The results speak volumes: Capital Dynamics cut their data preparation time by 83%. But the real game-changer was the downstream impact. Their risk models became more accurate, trading strategies more responsive, and compliance reporting more reliable - all because they finally had consistent, clean data to work with.
This shift represents a fundamental evolution in how financial firms handle data complexity. It's not just about processing speed - it's about creating a single source of truth in an industry where accuracy means millions.
Considerations for Data Transformation Rules AI Agents
Building effective data transformation rules into AI agents requires careful planning and deep understanding of both data structures and business logic. The complexity increases exponentially when dealing with multiple data sources, formats, and downstream dependencies.
Technical Challenges
Data quality issues often emerge as the primary technical hurdle. Raw data rarely arrives in a pristine state - missing values, inconsistent formats, and encoding problems can break even well-designed transformation rules. AI agents need robust error handling and validation mechanisms to maintain data integrity.
Schema evolution presents another significant challenge. As source systems change over time, transformation rules must adapt without breaking existing processes. Building flexibility into the rules engine while maintaining backwards compatibility requires sophisticated version control and testing protocols.
Operational Challenges
Performance optimization becomes critical at scale. Complex transformation rules can create processing bottlenecks, especially when dealing with real-time data streams. Teams need to carefully balance transformation complexity against latency requirements.
Monitoring and debugging transformed data requires specialized tooling. When issues occur, teams need visibility into each step of the transformation process to identify root causes. This means implementing comprehensive logging and observability solutions.
Implementation Best Practices
Start with a clear data governance framework. Define ownership, access controls, and quality standards before implementing transformation rules. This foundation helps prevent downstream issues and ensures compliance requirements are met.
Build incremental validation into the transformation pipeline. Rather than attempting to validate all rules at once, implement checkpoints throughout the process. This approach makes troubleshooting easier and helps maintain data quality.
Future-Proofing Considerations
Data transformation needs evolve as businesses grow. Design rules with modularity in mind, allowing for easy updates and extensions. Consider implementing a rules engine that supports both declarative and programmatic transformations to handle varying complexity levels.
Machine learning models can help optimize transformation rules over time. By analyzing patterns in data quality issues and transformation failures, AI agents can suggest improvements and automatically adjust rules within defined parameters.
The Future of AI-Powered Data Operations
The integration of AI Agents into data transformation represents a quantum leap in how organizations handle their data operations. The shift from manual coding to intelligent, adaptive systems isn't just about efficiency - it's about unlocking new possibilities in data utilization. As these digital teammates continue to evolve, they're creating a new paradigm where data transformation becomes more accessible, reliable, and powerful. The organizations that embrace this shift aren't just solving today's data challenges; they're positioning themselves for tomorrow's opportunities in the data-driven economy.


