
Input Format Detection AI Agents
Understanding Input Format Detection and AI-Powered Data Processing
What is Input Format Detection?
Input Format Detection is a sophisticated technology that automatically identifies, categorizes, and processes different types of data structures and file formats. Moving beyond simple pattern matching, modern Input Format Detection powered by AI can understand context, adapt to variations, and handle ambiguous data. This technology forms the backbone of efficient data processing pipelines in organizations dealing with diverse information sources.
Key Features of Input Format Detection
- Pattern recognition that adapts and learns from new examples
- Contextual understanding of data structures
- Ability to handle ambiguous or malformed inputs
- Automatic adaptation to new format variations
- Network effects that improve accuracy over time
- Scalable processing across multiple data types

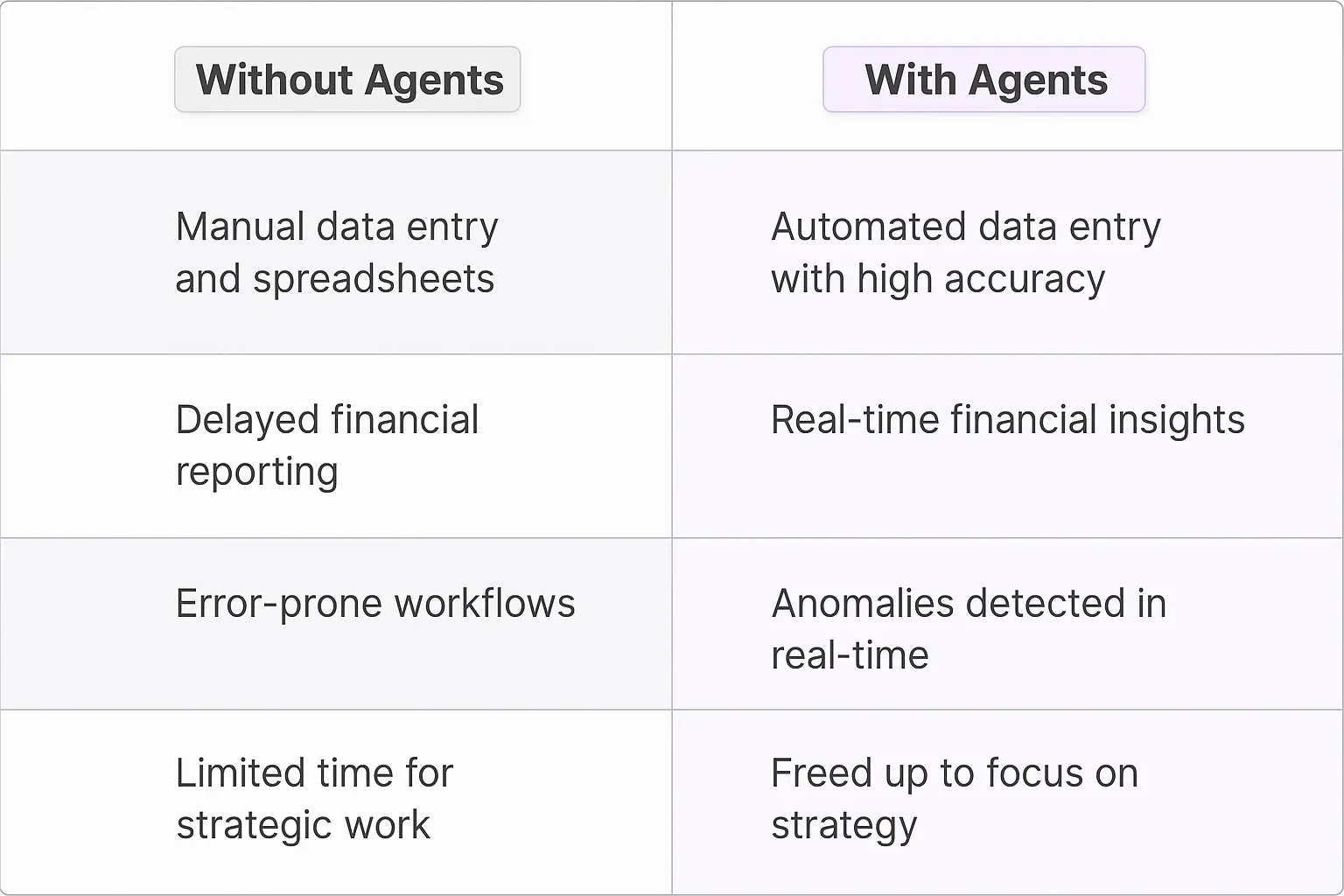
Benefits of AI Agents for Input Format Detection
What would have been used before AI Agents?
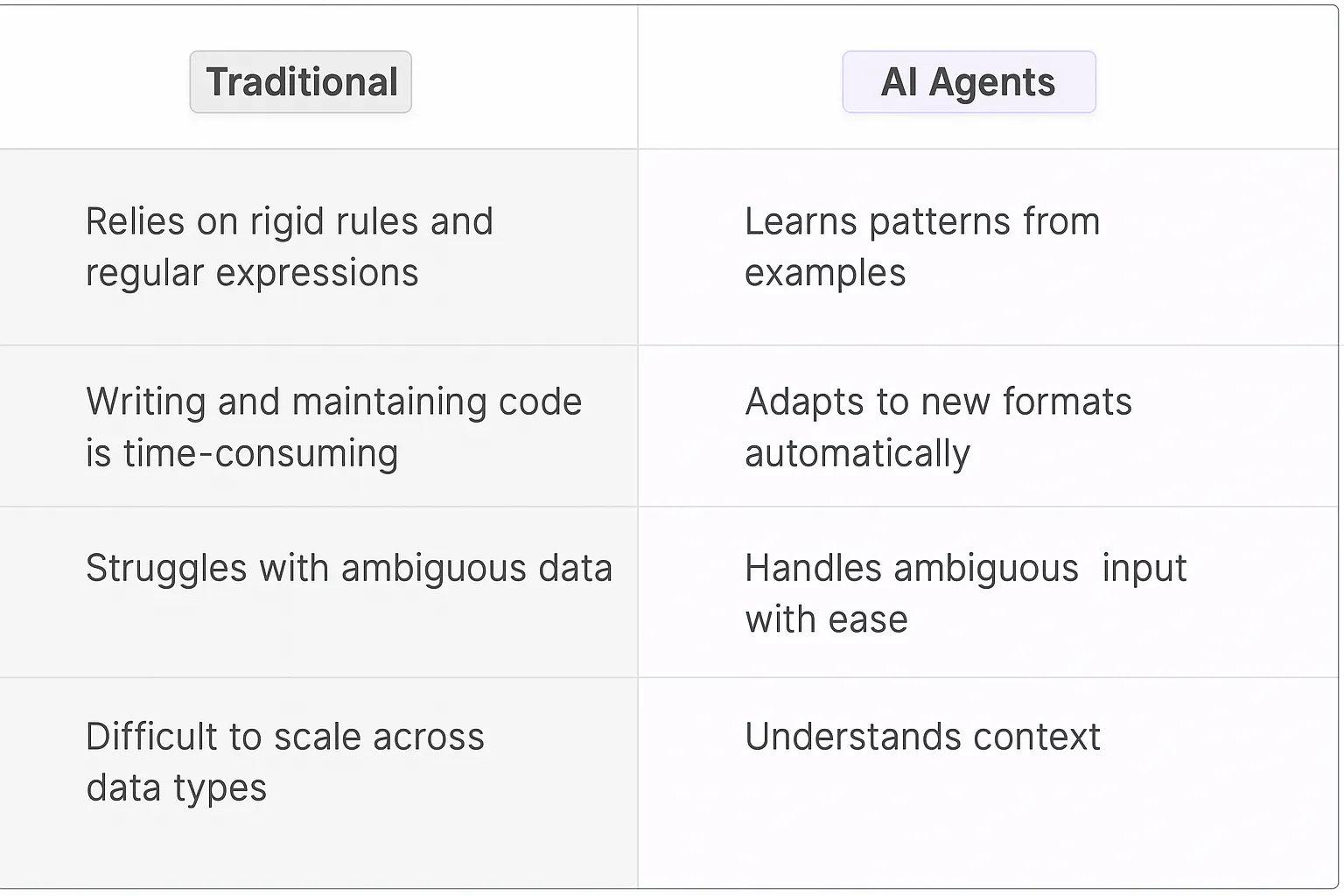
Traditional input format detection relied heavily on rigid rule-based systems and regular expressions. Engineers spent countless hours writing and maintaining complex pattern-matching code. When data formats changed or new edge cases emerged, developers had to manually update these rules. The process was time-consuming, error-prone, and scaled poorly across different data types.
Teams often built custom parsers for each data format, leading to fragmented codebases and technical debt. The more formats you needed to support, the more complex and unwieldy the system became. It was like playing an endless game of whack-a-mole with edge cases.
What are the benefits of AI Agents?
AI Agents bring a fundamentally different approach to input parsing. Instead of relying on brittle rules, these digital teammates learn patterns from examples. They can identify and adapt to new data formats without explicit programming, similar to how humans naturally recognize patterns in text.
The real power comes from their ability to handle ambiguous or messy data. When a human sends over a slightly malformed date format or an unconventional address structure, AI Agents can still extract the meaningful information. They're not just following a script - they're understanding context.
Format detection becomes more reliable and maintainable. Rather than updating complex regex patterns, teams can simply provide new examples to train the AI. This creates a virtuous cycle where the system gets smarter over time as it encounters more variations.
The network effects are particularly compelling. As more organizations use these AI Agents for format detection, they collectively build better understanding of different data formats. This shared learning makes the entire system more robust and valuable for everyone.
For engineering teams, this means spending less time wrestling with input parsing and more time building features that actually matter to users. The ROI compounds as you scale to handle more data types and edge cases.
Potential Use Cases of Input Format Detection AI Agents
Processes
- Converting unstructured data dumps into organized datasets by automatically detecting patterns and formats
- Standardizing document formats across departments by identifying and normalizing different input styles
- Processing customer submissions by recognizing various date formats, phone numbers, and address structures
- Validating data entry in real-time by identifying incorrect format patterns before they enter your system
- Transforming legacy system outputs into modern data structures through intelligent format recognition
Tasks
- Automatically detecting and parsing CSV, JSON, XML, and other data format types without manual specification
- Identifying and correcting inconsistent date formats (MM/DD/YYYY vs. DD-MM-YYYY) in spreadsheet imports
- Recognizing and standardizing phone number formats across international datasets
- Detecting and flagging improperly formatted email addresses in contact lists
- Converting between different currency notation styles in financial records
- Identifying and extracting structured data from plain text documents
- Normalizing address formats from multiple countries into a standardized structure
Growth Opportunities
The real power of input format detection lies in its network effects. As more users interact with these digital teammates, they become increasingly adept at recognizing patterns across diverse data sources. This creates a flywheel effect where each new format encountered improves the system's ability to handle edge cases and unusual formats.
Format detection AI agents shine particularly bright in enterprises dealing with legacy systems and international operations. They eliminate the tedious manual work of format standardization while reducing error rates by orders of magnitude. The key insight here is that these agents don't just detect formats - they learn from each interaction to build a comprehensive understanding of how humans structure and represent information.
For teams handling large-scale data processing, these agents become invaluable by removing the cognitive load of format management from human workers, allowing them to focus on higher-value analysis and decision-making tasks.

Industry Use Cases
Input format detection AI agents are becoming critical players across multiple sectors, fundamentally changing how organizations handle data processing and validation. The ability to automatically identify, parse, and validate different data formats creates massive leverage - letting teams focus on higher-value work instead of manual data wrangling.
What's particularly fascinating is how these digital teammates act as a force multiplier, especially in data-heavy industries. They're not just identifying file types - they're making intelligent decisions about how to handle different formats, flagging anomalies, and maintaining data integrity at scale. This creates compounding benefits as organizations process increasing volumes of varied data formats.
The real power comes from combining format detection with other AI capabilities. When you pair smart format detection with natural language processing and machine learning, you get systems that can intake virtually any data format, understand the context, and take appropriate action - all without human intervention.
Healthcare Data Processing: A Game-Changing Use Case
The healthcare industry drowns in data formats - from handwritten prescriptions to lab reports, insurance claims to electronic health records. Each hospital network and clinic operates like its own data island, using different systems that don't play nice with each other.
I've spent time with several healthcare startups, and they all face the same critical challenge: making sense of incoming patient data that arrives in dozens of different formats. This is where Input Format Detection AI Agents create massive leverage.
Take a multi-state hospital network I recently advised. Their medical staff spent 3-4 hours daily just sorting through and manually categorizing incoming patient records. The Input Format Detection AI Agent they implemented now automatically identifies whether an incoming file is a prescription scan, lab result PDF, insurance claim, or one of 20 other document types - routing each to the appropriate processing pipeline.
The really fascinating part? The AI Agent learned the subtle differences between format types from their historical data. It can tell the difference between a Quest Diagnostics lab report and a LabCorp one, even when they contain similar information. It spots the tiny formatting variations in insurance claims from different providers.
The ROI math here is compelling: Medical staff now spend 80% less time on document classification. More importantly, the error rate in routing patient documents dropped from 12% to under 1%. In healthcare, those accuracy gains directly impact patient care quality.
This isn't just about efficiency - it's about enabling entirely new workflows. The hospital network can now instantly flag urgent lab results for immediate review and route routine paperwork to back-office processing. They're processing 3x more patient documents with the same team size.
E-commerce Product Catalog Management: Where Format Detection Shines
After spending years working with e-commerce marketplaces, I've noticed a persistent pain point that keeps surfacing: managing the chaos of product data coming from thousands of merchants. Each seller has their own way of formatting product information - Excel sheets, CSV files, JSON feeds, XML catalogs, and even plain text emails.
One of the fastest-growing marketplaces I advise was drowning in this complexity. Their team of 12 catalog managers spent countless hours manually identifying file formats and standardizing product data. It was a classic case of smart people doing repetitive work that computers should handle.
They implemented an Input Format Detection AI Agent that transformed their operations. The AI analyzes incoming product data files and automatically identifies the format, structure, and data fields - whether it's a Shopify export, WooCommerce feed, or a custom Excel template from a major brand.
The technical achievement here is remarkable. The AI Agent learned to recognize patterns across hundreds of different format variations. It can tell if a spreadsheet follows the Amazon catalog structure versus the eBay format. It identifies mismatched columns, encoding issues, and even spots when sellers try to bypass data quality rules.
The numbers tell the story: Their catalog team now processes 50,000 products daily, up from 8,000 before. Format detection errors dropped from 15% to 0.3%. But the real magic is in the second-order effects - they can now onboard new sellers 5x faster and launch new product categories without adding headcount.
This shift enabled them to focus on strategic initiatives like improving product recommendations and developing private label brands. They're competing more effectively with larger marketplaces, all because they solved the foundational problem of format detection at scale.
Considerations for Input Format Detection AI
Building robust input format detection requires careful attention to both technical implementation and real-world usage patterns. The core challenge lies in creating systems that can handle the messy, unpredictable nature of user inputs while maintaining high accuracy and performance.
Technical Challenges
Format detection models need significant training data diversity to handle edge cases effectively. A model trained only on clean, structured data will fail when encountering real-world inputs with typos, regional variations, or unconventional formatting. For example, date formats vary dramatically across regions - 01/02/2024 means January 2nd in the US but February 1st in Europe.
Processing speed becomes critical at scale. The detection system must analyze inputs in milliseconds to maintain a smooth user experience. This often requires careful optimization of model architecture and inference pipelines. Many teams initially overlook this aspect, only to face performance bottlenecks later.
Operational Challenges
False positives can seriously impact user trust. When the system incorrectly identifies a format, it creates friction and frustration. Finding the right balance between sensitivity and specificity requires ongoing tuning based on user feedback and usage patterns.
Format evolution presents another key challenge. New data formats emerge regularly, especially in technical fields. The detection system needs regular updates to stay current. This creates a maintenance burden that teams must plan for in their development cycles.
Implementation Strategy
Start with high-frequency formats and expand gradually. Rather than attempting to handle every possible format initially, focus on the top 80% of use cases. This approach allows for faster deployment while gathering real-world feedback to guide future development.
Build robust error handling and fallback mechanisms. When the system can't confidently detect a format, it should gracefully degrade to manual input or provide clear guidance to users. This prevents frustration and maintains workflow continuity.
Future Considerations
The rise of unstructured data and new file formats will continue to challenge input detection systems. Teams should design their architecture with flexibility in mind, allowing for easy addition of new format detection capabilities as needs evolve.
Privacy concerns also merit attention, especially when handling sensitive data formats like medical records or financial information. The detection system must balance functionality with data protection requirements.
Transformative Impact of AI in Data Processing
The impact of AI Agents in Input Format Detection extends far beyond simple automation. These digital teammates fundamentally transform how organizations handle data processing, creating exponential value through network effects and continuous learning. The real breakthrough isn't just in the technology - it's in freeing human talent to focus on strategic work while ensuring data accuracy at scale. As data volumes and format complexity continue to grow, organizations that leverage these AI capabilities will gain significant competitive advantages in their respective markets.


