
Document Text Extraction AI Agents
Understanding AI-Powered Document Processing
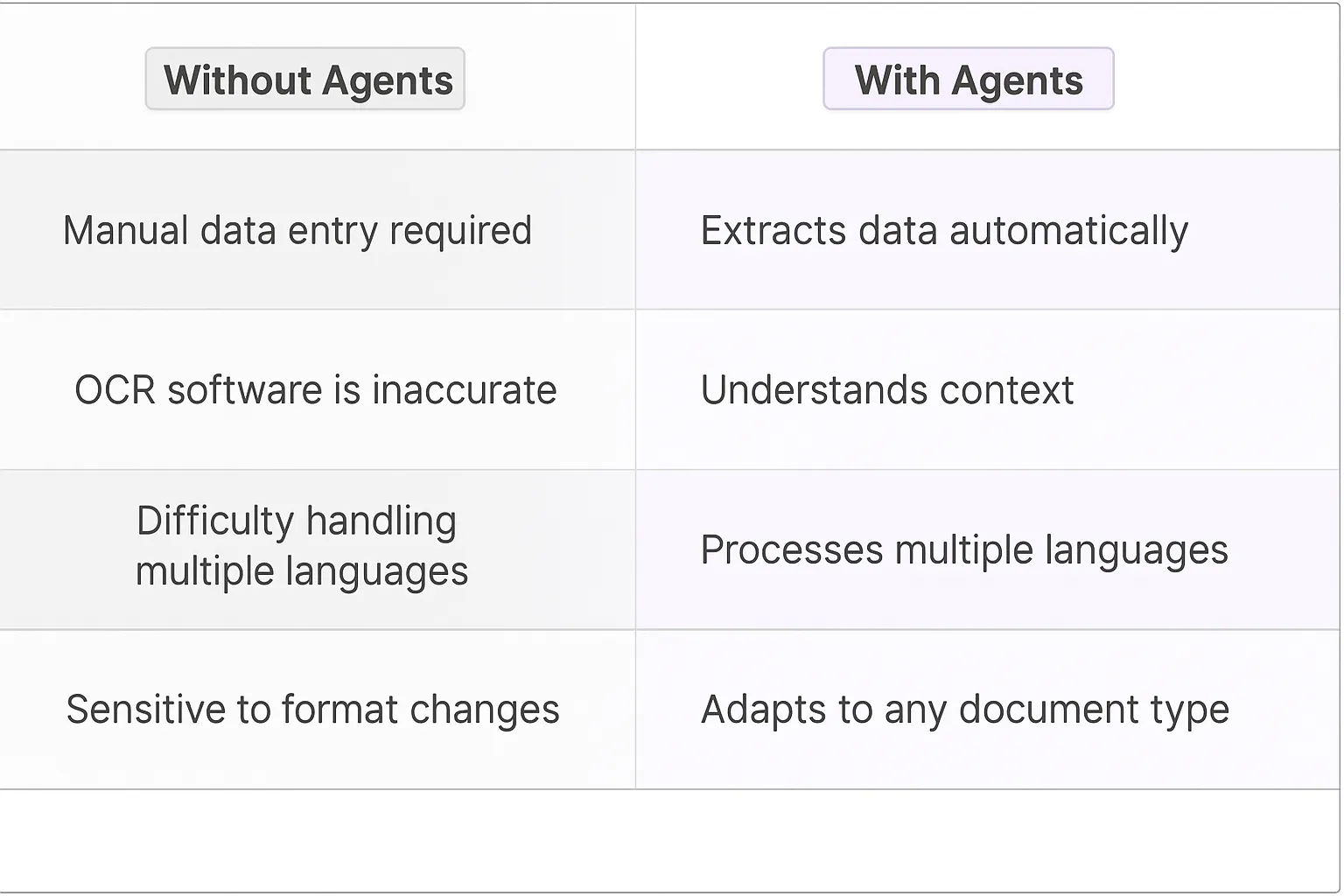
Document text extraction powered by AI agents represents a fundamental shift in how organizations process information. This technology combines computer vision, natural language processing, and machine learning to automatically identify, extract and structure data from documents. Unlike traditional OCR tools, modern AI-powered extraction understands context, handles multiple languages, and learns from each interaction to improve accuracy over time.
Key Features of Document Text Extraction
- Intelligent context recognition that understands document structure and relationships between data elements
- Multi-language support with ability to process different scripts and writing styles
- Adaptive learning capabilities that improve accuracy through continuous processing
- Integration with existing workflows and systems
- Built-in quality control and validation mechanisms
- Ability to handle both structured and unstructured document formats

Benefits of AI Agents for Document Text Extraction
What would have been used before AI Agents?
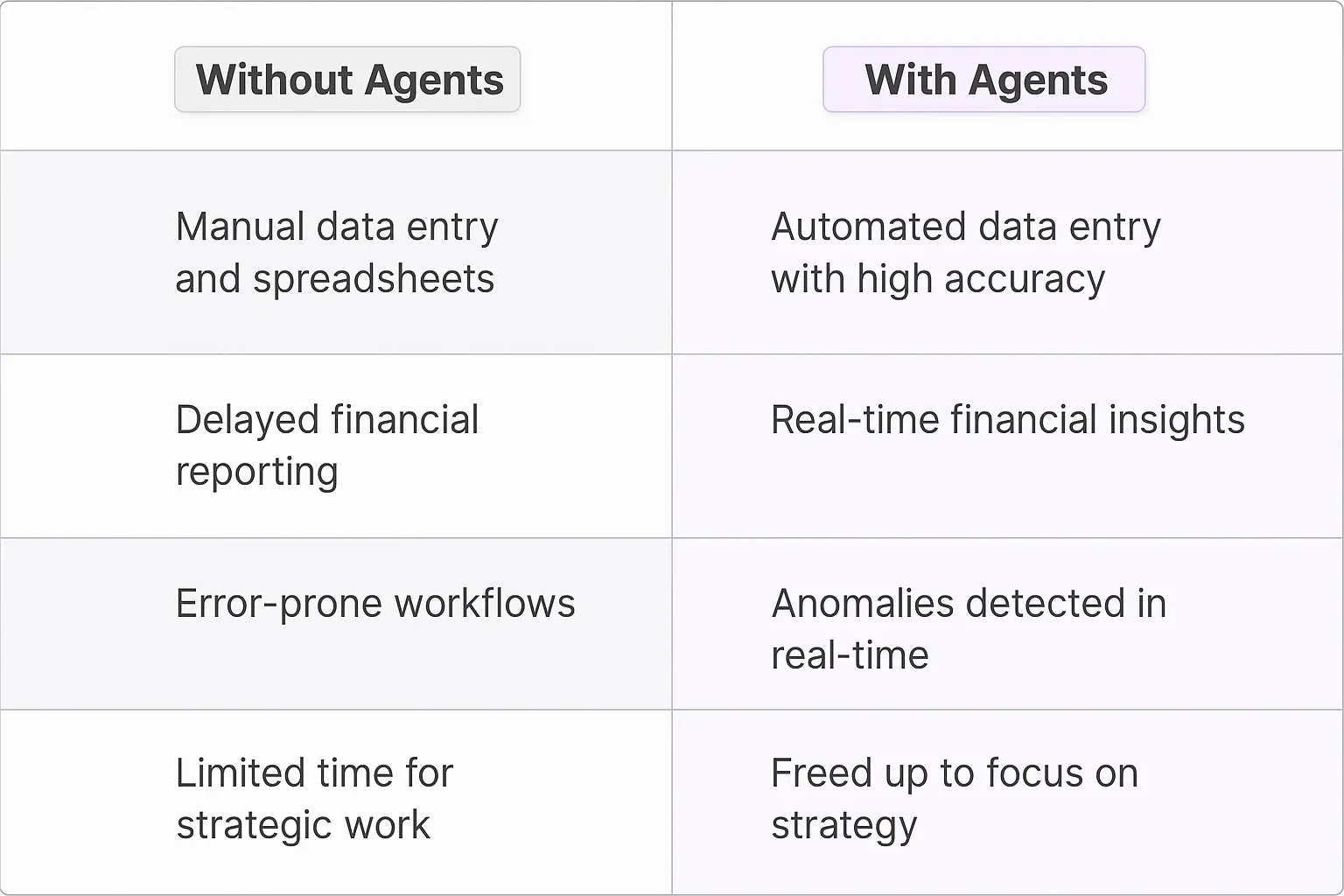
The old-school approach to document text extraction was painful - we're talking manual data entry, OCR software that barely worked, and teams of people copying and pasting between documents. Companies would spend countless hours training staff on complex rule-based systems that broke whenever document formats changed. The worst part? These legacy solutions couldn't handle handwriting, different languages, or documents with mixed formats.
What are the benefits of AI Agents?
AI Agents for document extraction represent a massive leap forward in how we process information. These digital teammates can now:
- Pull meaning from context - they understand document structure and can identify relevant information even when it's in unexpected places
- Handle multiple languages and writing styles simultaneously - no need for separate systems or workflows
- Learn and adapt from corrections, getting smarter with each document processed
- Extract data from both structured and unstructured documents - from neat tables to messy handwritten notes
- Work 24/7 without fatigue or errors that come from manual processing
The network effects here are fascinating - each organization using these AI Agents contributes to a broader understanding of document formats and extraction patterns. This creates a flywheel effect where the technology becomes more valuable as adoption grows.
What's particularly interesting is how these AI Agents are changing team dynamics. Instead of staff spending hours on mind-numbing data entry, they're now focusing on exception handling and quality control - much higher-value work that actually requires human judgment.
The ROI isn't just in time saved - it's in the accuracy and consistency of the extracted data, which flows through to better decision-making and reduced downstream errors. This is a classic example of technology not just making existing processes faster, but fundamentally changing how work gets done.
Potential Use Cases of Document Text Extraction AI Agents
Processes
- Converting scanned contracts into searchable digital documents while maintaining formatting and legal clause structure
- Extracting financial data from invoices and receipts for automated expense reporting and bookkeeping
- Pulling key information from resumes and CVs to populate applicant tracking systems
- Digitizing handwritten notes and converting them into editable text while preserving the original layout
- Processing medical records and extracting patient history, diagnoses, and treatment plans into structured data
Tasks
- Analyzing PDF reports to create executive summaries and data visualizations
- Converting photographed business cards into contact database entries
- Extracting tables and charts from research papers into spreadsheet formats
- Creating searchable archives from scanned historical documents
- Pulling product specifications from technical manuals into structured databases
- Converting meeting minutes into action items and task lists
- Extracting warranty information from product documentation
The Growth Impact of Document Extraction AI
Document extraction AI represents a critical inflection point in how organizations handle information processing. When we look at the adoption curves of transformative technologies, we see a familiar pattern: what starts as a nice-to-have tool becomes mission-critical infrastructure.
The most compelling aspect is the network effect created when document extraction AI is deployed across an organization. Each successfully processed document improves the system's accuracy, creating a flywheel effect that compounds value over time. Teams that implement these digital teammates for document processing typically see a 60-80% reduction in manual data entry time.
What's particularly fascinating is how document extraction AI creates new workflows that weren't previously possible. Organizations can now process thousands of documents in minutes, unlocking new use cases and business models. This isn't just about doing old things faster – it's about enabling entirely new capabilities.
The key to success lies in understanding that document extraction AI isn't just a point solution but a foundational layer that transforms how organizations handle information. The winners in this space will be those who integrate these capabilities deeply into their core processes rather than treating them as bolt-on solutions.

Industry Use Cases
Document text extraction AI agents are fundamentally changing how organizations handle their most valuable information assets. The ability to intelligently parse and extract meaningful data from documents opens up entirely new possibilities across sectors. Let me break down the transformative impact I'm seeing firsthand:
When you look at how companies actually deploy these AI agents, the applications are incredibly diverse and sophisticated. They're not just scanning documents - they're enabling entirely new operational models. The key is that these digital teammates can understand context, identify patterns, and extract structured data from even the most complex unstructured documents.
What makes this particularly powerful is how it removes traditional bottlenecks in document processing. Rather than having skilled knowledge workers manually reviewing and extracting data, organizations can deploy AI agents that handle the heavy lifting with remarkable accuracy. This creates a multiplier effect where human expertise can be applied to higher-value activities.
The versatility of AI agents in document text extraction makes them valuable across various industries. The following industry-specific use cases showcase how AI can enhance core document processing workflows while maintaining accuracy and compliance.
Legal Document Analysis: Transforming Contract Review
Law firms process thousands of contracts weekly, with junior associates traditionally spending 60% of their time manually reviewing documents. Document extraction AI agents fundamentally change this dynamic by intelligently parsing through complex legal agreements in seconds.
A mid-sized law firm in Boston implemented document extraction AI to analyze merger and acquisition contracts. The AI agent scans incoming documents, identifies key clauses, payment terms, and legal obligations, then generates structured data that feeds directly into their case management system. What previously took 4-6 hours of associate time now happens in under 3 minutes.
The real magic happens in how the AI agent handles edge cases. When reviewing a 90-page acquisition agreement, it flagged unusual indemnification language buried on page 73 that didn't match standard templates. This early warning system helped the firm's partners identify a material risk that could have been easily missed in manual review.
Beyond just time savings, the AI agent creates a searchable knowledge base of every contract review it processes. Partners can now query across thousands of agreements to understand market trends in deal terms or quickly surface precedent language for new contracts. This network effect compounds over time - each new document analyzed makes the system smarter.
The ROI metrics tell the story: 85% reduction in initial contract review time, 90% accuracy in extracting key terms (higher than human baseline), and junior associates now focusing on higher-value strategic work instead of document processing. Most importantly, clients receive faster turnaround times without sacrificing quality of review.
This shift represents a fundamental evolution in how legal work gets done. Document extraction AI isn't replacing lawyers - it's giving them superpowers to handle higher volumes of work with greater consistency and insight than ever before.
Healthcare Claims Processing: Unlocking Medical Document Intelligence
I've been tracking an interesting pattern in healthcare claims processing that perfectly illustrates the power of document extraction AI. A regional healthcare network handling 50,000+ claims monthly completely transformed their operations by deploying these digital teammates.
The old process was painful - medical coders spent 12-15 minutes per claim manually extracting diagnosis codes, treatment details, and insurance information from a mix of handwritten notes, lab reports, and electronic health records. With 40% of claims requiring rework due to human error, the bottlenecks were severe.
Their document extraction AI agent now processes these same claims in under 30 seconds. The really fascinating part? It handles messy doctor's handwriting better than experienced coders, using pattern recognition trained on millions of medical documents. When it encounters unclear text, it flags it for human review rather than making assumptions.
The network effect is what makes this truly powerful. Every processed document makes the system more intelligent about medical terminology, common treatment patterns, and provider-specific documentation styles. After 6 months, the AI agent learned to identify subtle indicators of potential claim denials before submission - like missing pre-authorization codes or incomplete documentation.
The metrics are compelling: 94% reduction in processing time, error rates down from 40% to 3%, and $2.1M annual savings in administrative costs. But the human impact is even more interesting. Medical coders now focus on complex cases and quality assurance, using their expertise where it matters most.
This shift represents the next evolution in healthcare administration. The AI agent handles the heavy lifting of claims processing, while human experts focus on judgment-intensive tasks like appeals and policy compliance. It's a perfect example of how AI amplifies rather than replaces human capabilities.
Considerations for Document Text Extraction AI Agents
Technical Challenges
Document text extraction involves complex technical hurdles that many teams underestimate. The first major challenge is handling diverse document formats - from scanned PDFs with multiple columns to images with handwritten notes. Each format requires different processing approaches and OCR capabilities. We've seen teams struggle when their extraction agents can't handle documents with tables, charts, or non-standard layouts.
Language processing adds another layer of complexity. Documents often contain domain-specific terminology, abbreviations, and contextual references that standard NLP models might misinterpret. For example, medical documents use specific terminology that can confuse general-purpose extraction models.
Operational Challenges
The real-world implementation of document extraction agents faces several operational hurdles. Processing speed becomes critical when dealing with large document volumes. Teams need to balance accuracy with performance - too much precision can create bottlenecks, while rushing through documents leads to errors.
Data privacy presents another significant challenge. Document extraction agents often handle sensitive information like financial records or personal data. Organizations must implement robust security measures and ensure compliance with regulations like GDPR or HIPAA. This includes secure storage, encrypted processing, and careful handling of extracted data.
Integration Requirements
Successful document extraction depends heavily on seamless integration with existing systems. The extraction agent needs to work with document management systems, cloud storage solutions, and downstream processing tools. Many organizations struggle with creating smooth handoffs between the extraction agent and human reviewers who need to validate critical information.
Version control and document tracking become essential when multiple stakeholders interact with the extracted data. Teams need systems to track which documents have been processed, manage extraction errors, and handle document updates or revisions.
Quality Control Considerations
Maintaining high accuracy requires robust quality control processes. Organizations need to implement validation workflows, error checking, and continuous monitoring of extraction accuracy. This often means developing custom validation rules for different document types and establishing clear processes for handling exceptions.
Regular model retraining becomes necessary as document formats evolve and new edge cases emerge. Teams need to collect and label new training data, track performance metrics, and iterate on their extraction models to maintain accuracy over time.
Transforming Information Processing Through AI Integration
The impact of document extraction AI agents extends far beyond simple automation. These digital teammates are fundamentally reshaping how organizations handle information processing, creating new possibilities for scaling operations and unlocking valuable insights from document repositories. The network effects and continuous learning capabilities mean the technology becomes more valuable over time, creating sustainable competitive advantages for early adopters.
Looking ahead, organizations that deeply integrate document extraction AI into their core processes will pull ahead of those treating it as just another point solution. The key to success lies in understanding this isn't just about processing documents faster - it's about transforming how we work with information at scale.


