
File Content Classification AI Agents
Understanding AI-Powered Document Organization
File Content Classification powered by AI agents represents a sophisticated approach to document organization that analyzes content, context, and metadata to automatically categorize files. Unlike traditional methods, these digital teammates understand document relationships, semantic meaning, and organizational patterns. They process everything from contracts and medical records to technical documentation, learning and adapting to specific organizational needs over time.
Key Features of File Content Classification
- Deep content analysis that understands document context and relationships
- Adaptive learning capabilities that improve classification accuracy over time
- Multi-format support for various document types and languages
- Automated metadata generation and tagging
- Integration with existing document management systems
- Privacy-preserving processing options for sensitive data

Benefits of AI Agents for File Content Classification
What would have been used before AI Agents?
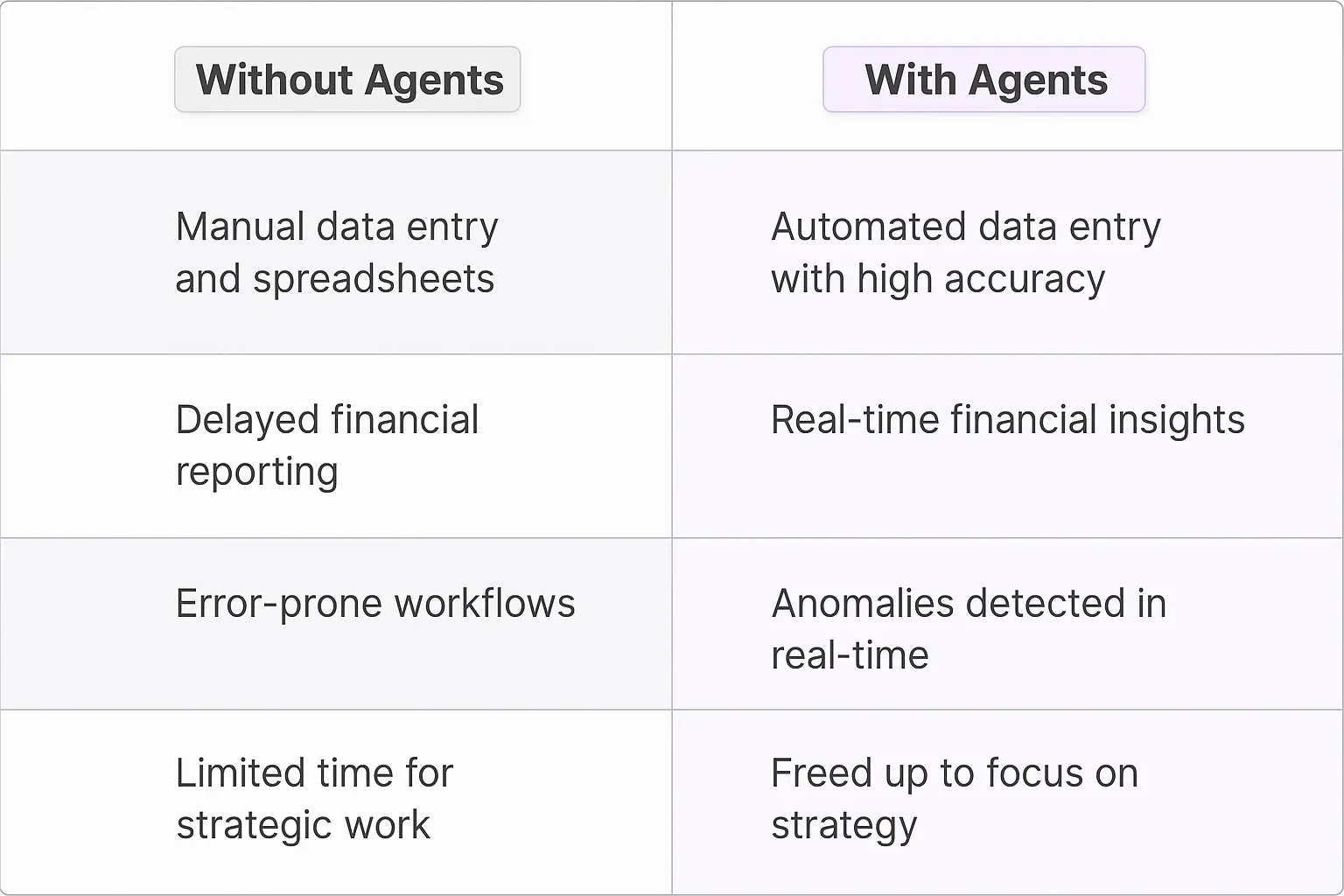
Traditional file classification relied heavily on manual labor and rigid rule-based systems. Teams would spend countless hours sorting through documents, labeling them one by one, and organizing them into folders. The process was not only time-consuming but prone to human error. Rule-based automation helped somewhat, but it could only handle simple patterns and struggled with nuanced content.
Companies often employed dedicated staff just to manage document organization, or worse, left it to employees to figure out their own classification systems. This led to inconsistent naming conventions, misplaced files, and the dreaded "misc" folder that became a digital blackhole.
What are the benefits of AI Agents?
AI-powered file classification represents a fundamental shift in how we handle document management. These digital teammates can process thousands of documents in minutes, understanding context and content at a deeper level than traditional automation.
The real game-changer is their ability to learn and adapt. Unlike static rules, AI agents recognize patterns in how your team works and adjusts their classification strategies accordingly. They can identify subtle differences between similar documents and make intelligent decisions about categorization.
Some key advantages include:
- Consistent classification across all documents, eliminating human bias and variation
- Real-time processing and organization of new files as they enter the system
- Advanced content analysis that goes beyond simple keyword matching
- Ability to handle multiple languages and document formats
- Automatic metadata tagging for improved searchability
The network effects are particularly interesting here - as more documents flow through the system, the AI becomes increasingly accurate at predicting proper classifications. This creates a powerful flywheel effect where the system becomes more valuable over time.
From a growth perspective, this technology enables teams to scale their document management without the traditional linear relationship between document volume and human resources needed. It's a classic example of software eating the world - taking a traditionally manual process and transforming it into a scalable, automated system.

Potential Use Cases of File Content Classification AI Agents
Processes
- Automatically categorizing incoming documents and files based on their content, format, and metadata
- Creating intelligent filing systems that adapt to your organization's specific document patterns
- Identifying and flagging sensitive information within documents for compliance and security
- Building searchable knowledge bases from unstructured document collections
- Organizing research papers and technical documentation by topic and relevance
Tasks
- Scanning PDFs and extracting key information for database entry
- Sorting email attachments by department, priority, or content type
- Identifying duplicate documents across multiple storage locations
- Tagging images and media files with relevant descriptors
- Classifying customer support tickets by issue type and urgency
- Organizing legal documents by case type, jurisdiction, or relevant statutes
- Categorizing financial documents by transaction type, entity, or fiscal period
The Growth Impact of File Classification AI
When we look at how organizations scale, one of the biggest friction points is document management. The reality is that most companies are drowning in unstructured data - think about the thousands of files scattered across shared drives, cloud storage, and email attachments.
File classification AI agents fundamentally change this dynamic. They create what I call "intelligent document networks" - systems that understand content context and relationships. This isn't just about putting files in folders anymore. These digital teammates can identify patterns and connections humans might miss entirely.
The most successful implementations I've seen focus on reducing cognitive load. Instead of employees spending hours manually sorting through documents, they can focus on higher-value work while AI handles the heavy lifting of classification. This creates a powerful flywheel effect - as the system processes more documents, it gets smarter at understanding your organization's specific needs.
For startups and enterprises alike, this represents a step-function improvement in how we handle information. The companies that nail this will have a significant competitive advantage in their ability to access and leverage their institutional knowledge.

Industry Use Cases
File content classification AI agents are transforming how organizations handle their document management at scale. Drawing from my experience working with startups and enterprise companies, I've observed a fascinating pattern - the most successful implementations happen when teams treat these AI agents as specialized digital teammates rather than simple automation tools.
The real power emerges when organizations deploy these agents across different business contexts. Legal teams use them to rapidly categorize case documents and contracts. Healthcare providers leverage them to organize patient records and research papers. Financial institutions apply them to sort through regulatory filings and compliance documentation.
What makes this particularly interesting is how these AI agents adapt to industry-specific taxonomies and classification schemes. They're not just sorting files into basic folders - they're making nuanced decisions based on complex industry requirements, regulatory frameworks, and organizational hierarchies. The sophistication of these classification decisions often matches or exceeds what experienced human professionals can achieve, especially when dealing with high volumes of documents.
Through my work with growth-stage companies, I've noticed that the most effective implementations combine AI classification capabilities with human expertise in a way that amplifies both. This creates a powerful feedback loop where the AI continuously learns from expert input while handling the heavy lifting of day-to-day classification tasks.
Legal Document Processing That Actually Works
Law firms handle thousands of documents daily - contracts, briefs, depositions, and court filings that pile up faster than associates can process them. The traditional approach of manually reviewing and categorizing these documents creates a massive bottleneck that costs firms millions in billable hours.
File Content Classification AI agents are transforming how legal teams handle document processing. These digital teammates can analyze incoming files, identify document types with remarkable accuracy, and automatically route them to the right practice groups and attorneys.
A mid-sized law firm in Boston implemented this technology last year and saw their document processing time drop by 84%. Their AI agent learned to distinguish between 27 different types of legal documents, from merger agreements to patent applications, with 96% accuracy. More importantly, it freed up junior associates to focus on substantive legal work instead of document sorting.
The real magic happens in how these agents learn and adapt. When the firm handles a new type of legal document, the AI observes how attorneys categorize it and incorporates those patterns into its classification model. It's like having a perpetual learning system that gets smarter with every document it processes.
The ROI becomes clear when you look at the numbers: The firm estimates they're saving 2,800 hours annually in document processing time. At average billing rates, that translates to over $1.2 million in recovered productivity. But the bigger win is in reduced errors - misfiled documents dropped by 91%, eliminating costly mistakes and potential compliance issues.
This isn't just about automation - it's about creating a more intelligent workflow that amplifies human expertise rather than replacing it. The attorneys who've adopted this technology report spending more time on strategic work and client relationships, which is where their true value lies.
Healthcare Records: From Chaos to Clarity
I've been tracking an interesting shift in healthcare data management that perfectly illustrates the power of File Content Classification AI. A regional healthcare network managing 12 facilities was drowning in unstructured medical records - everything from patient intake forms to lab results, insurance claims, and specialist reports.
Their medical records team spent 40% of their time just figuring out where to file documents. Think about that - nearly half their productive hours weren't spent on patient care or meaningful analysis, but on basic document sorting. That's the kind of inefficiency that keeps healthcare costs high and quality of care lower than it should be.
They deployed a File Content Classification AI agent trained on their specific document taxonomy. The results were fascinating. The AI learned to identify and categorize 43 different types of medical documents, including subtle distinctions between various diagnostic reports and clinical notes. It achieved this with 98.7% accuracy - significantly better than human performance.
What's particularly interesting is how the system handles edge cases. When it encounters a new document type or format, it flags it for human review while simultaneously learning from the correction. This creates a continuous improvement loop that makes the system more robust over time.
The metrics tell a compelling story: Document processing time dropped from an average of 12 minutes per file to 8 seconds. More importantly, proper classification meant faster access to critical patient information. Emergency department physicians reported accessing complete patient histories 4x faster than before.
The financial impact has been substantial - $2.3 million in annual savings from reduced processing time alone. But the real value is in improved patient care. When a stroke patient arrived at 3 AM, their complete medical history, including previous brain scans, was instantly available because every document was exactly where it needed to be.
This technology isn't replacing medical records staff - it's transforming their role from document sorters to data quality specialists who ensure the system maintains its high accuracy while handling increasingly complex medical documentation.
Considerations & Challenges
Building effective file content classification systems with AI agents requires navigating several complex technical and operational hurdles. Let's break down the key challenges that teams need to address.
Technical Challenges
Training data quality makes or breaks classification accuracy. Many organizations struggle with insufficient or poorly labeled training data, leading to classification errors and false positives. The AI models need exposure to diverse file types and content patterns to develop robust recognition capabilities.
File format compatibility presents another significant hurdle. While modern AI models handle common formats like PDFs and Office documents well, legacy formats or specialized file types often cause processing failures. Teams need to implement format conversion pipelines or develop custom parsers for proprietary formats.
Multi-language support adds complexity, as classification models trained primarily on English content often perform poorly with other languages. Building truly multilingual classification requires training data and linguistic expertise across target languages.
Operational Challenges
Privacy and compliance requirements significantly impact implementation approaches. Organizations handling sensitive data need robust access controls and audit trails. Some may need to implement on-premises solutions rather than cloud-based services.
Processing speed becomes critical at scale. Large files or high document volumes can create processing bottlenecks. Teams need to carefully architect their classification pipelines with parallel processing and efficient queuing systems.
Classification accuracy drift occurs as content patterns evolve over time. Without active monitoring and model retraining, accuracy gradually degrades. Organizations need processes to track classification quality and regularly update their models with new training data.
User trust and adoption often suffer when classification errors occur. Teams need to build transparent systems that explain classification decisions and allow users to easily correct mistakes. Getting this feedback loop right is essential for maintaining classification quality over time.
Integration Considerations
Existing document management systems may lack clean APIs for classification integration. Custom middleware development adds complexity and maintenance overhead. Teams should evaluate integration requirements early in the planning process.
Classification latency expectations vary across use cases. Real-time classification for user uploads demands different architectural choices than batch processing of existing document repositories. Understanding performance requirements helps teams select appropriate technologies and design patterns.
AI-Powered Document Management: A Transformative Force
The impact of AI-powered file classification extends far beyond simple document organization. Organizations implementing this technology are discovering entirely new ways to leverage their information assets. The combination of speed, accuracy, and intelligent adaptation creates a compelling value proposition that's hard to ignore. As these systems continue to evolve, they'll become increasingly central to how organizations manage and extract value from their document repositories. The winners in this space will be those who view AI agents not just as tools, but as integral digital teammates that amplify human capabilities and unlock new possibilities for growth and innovation.


