

Audio Analysis Audris
Agent Overview
AI-powered audio analysis agents are transforming market research by automating the extraction of insights from spoken word data. These agents analyze podcasts, interviews, focus groups, and customer calls to identify key themes, assess sentiment, and extract compelling quotes, enabling faster, more comprehensive, and data-driven market understanding.

Who this agent is for
This agent is ideal for market research firms, product development teams, marketing departments, and any organization that relies on qualitative audio data to understand customer needs, market trends, and competitive landscapes. It's particularly valuable for companies that conduct frequent customer interviews, run focus groups, or monitor brand mentions across podcasts and other audio platforms. Whether you're a small startup validating a new product idea or a large enterprise tracking brand perception, this agent provides scalable, efficient, and objective audio data analysis.
How this agent makes market research easier
Automate theme identification and topic modeling
Instead of manually listening to hours of audio recordings and coding for recurring themes, this agent automatically identifies key topics and subtopics discussed within the audio data. It uses advanced natural language processing (NLP) to group related concepts and surface the most prevalent themes, saving researchers countless hours of manual effort.
Quantify sentiment and emotional tone
Understanding the emotional context behind customer feedback is crucial for effective market research. This agent analyzes the sentiment expressed in audio recordings, identifying positive, negative, and neutral tones. It can also detect specific emotions like excitement, frustration, or satisfaction, providing a nuanced understanding of customer attitudes.
Extract impactful quotes and testimonials
Finding compelling quotes and testimonials from audio data can be time-consuming. This agent automatically identifies and extracts the most relevant and impactful quotes, saving researchers the effort of manually transcribing and reviewing recordings. These quotes can be used in marketing materials, presentations, and reports to illustrate key findings and support data-driven recommendations.
Benefits of AI Agents for Market Research
What would have been used before AI Agents?
Market researchers traditionally relied on manual methods to analyze audio data, which involved transcribing recordings, listening to them repeatedly, and manually coding for themes and sentiment. This process was time-consuming, expensive, and prone to human bias. Researchers often had to rely on small sample sizes due to the limitations of manual analysis, which could lead to inaccurate or incomplete insights.
What are the benefits of AI Agents?
AI agents offer several key benefits for market research. They automate the analysis of audio data, significantly reducing the time and cost associated with manual methods. They can process large volumes of data quickly and efficiently, enabling researchers to analyze more data and obtain more comprehensive insights. AI agents also provide objective and consistent analysis, eliminating human bias and ensuring the reliability of results.
Furthermore, AI agents can identify subtle patterns and relationships in the data that might be missed by human analysts. They can also provide real-time insights, allowing researchers to respond quickly to changing market conditions. By automating the analysis of audio data, AI agents free up researchers to focus on higher-level tasks such as interpreting results, developing strategies, and communicating findings to stakeholders.
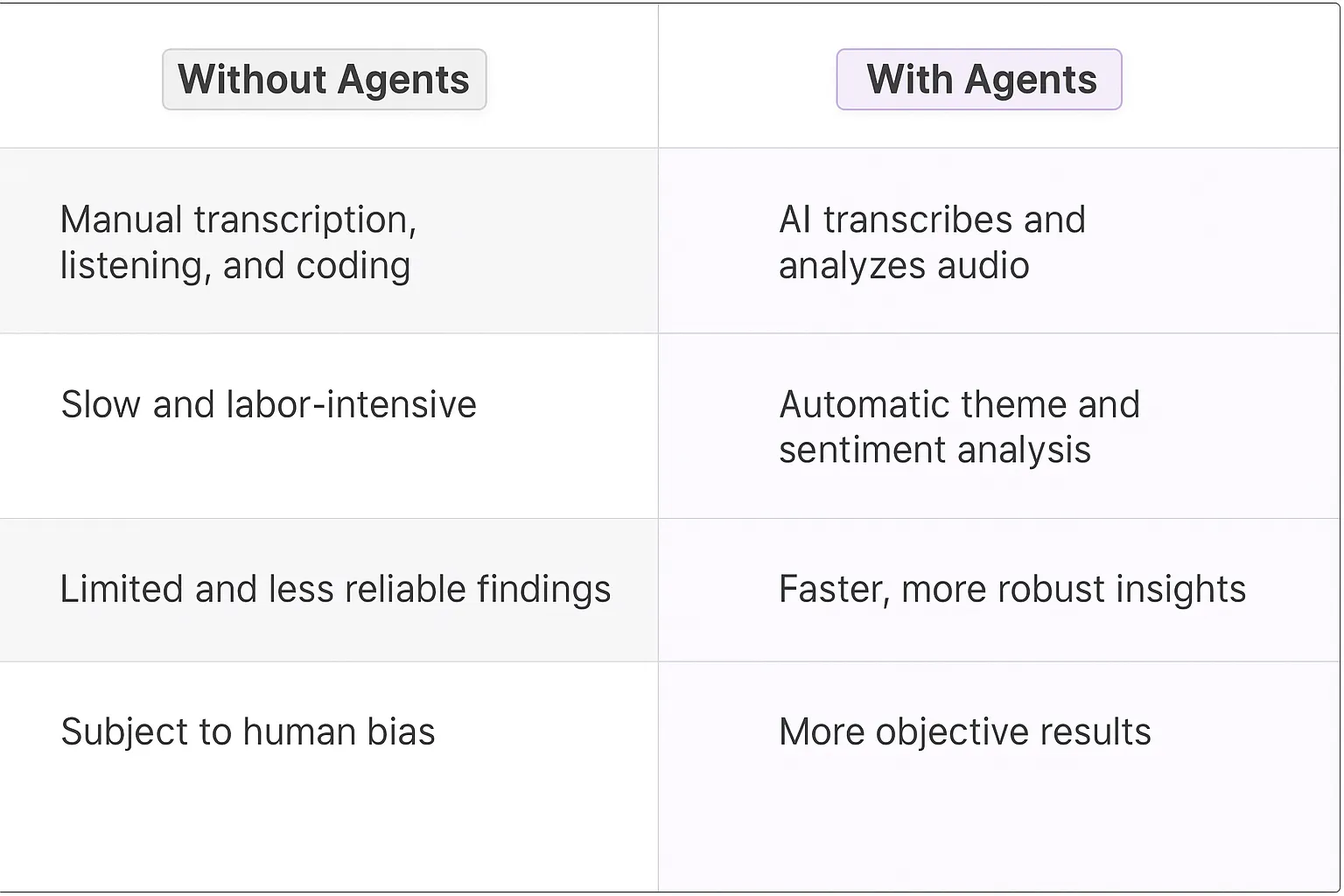
Traditional vs Agentic market research
Traditional market research using audio data involves manual transcription, listening, and coding, a process that is slow, expensive, and subject to human error. Researchers spend countless hours sifting through recordings to identify key themes and sentiments.
Agentic market research, on the other hand, leverages AI to automate these tasks. The AI agent quickly transcribes audio, identifies themes, analyzes sentiment, and extracts key quotes, providing researchers with actionable insights in a fraction of the time. This allows for larger datasets to be analyzed, leading to more robust and reliable findings. The agent also eliminates human bias, ensuring a more objective analysis.
Tasks that can be completed by an Audio Analysis Agent
An AI-powered audio analysis agent can perform a variety of tasks to streamline and enhance market research efforts. These tasks include:
- Transcription: Automatically transcribing audio recordings into text, eliminating the need for manual transcription.
- Theme Identification: Identifying recurring themes and topics within the audio data, providing insights into key areas of discussion.
- Sentiment Analysis: Analyzing the sentiment expressed in the audio, determining whether the speaker's tone is positive, negative, or neutral.
- Quote Extraction: Extracting relevant and impactful quotes from the audio, providing concrete examples to support research findings.
- Speaker Diarization: Identifying and differentiating between different speakers in the audio, allowing for analysis of individual perspectives.
- Keyword Detection: Identifying specific keywords and phrases within the audio, providing insights into specific topics of interest.
- Competitive Analysis: Analyzing audio data from competitors to identify their key messages, strengths, and weaknesses.
- Customer Feedback Analysis: Analyzing customer calls and interviews to identify areas for product improvement and customer satisfaction.
- Trend Identification: Identifying emerging trends and patterns in the audio data, providing insights into future market opportunities.
Things to Keep in Mind When Building an Audio Analysis Agent
Building an effective AI-powered audio analysis agent requires careful planning and execution. Here are some key considerations:
- Data Quality: Ensure that the audio data is of high quality, with minimal background noise and clear speech. Poor audio quality can significantly impact the accuracy of the agent's analysis.
- Training Data: Provide the agent with a large and diverse dataset of audio recordings to train on. The more data the agent has, the better it will be at identifying themes, analyzing sentiment, and extracting quotes.
- Customization: Customize the agent to meet your specific needs and requirements. This may involve training the agent on industry-specific terminology or adjusting the sensitivity of the sentiment analysis algorithm.
- Integration: Integrate the agent with your existing market research tools and workflows. This will allow you to seamlessly incorporate the agent's insights into your research process.
- Ethical Considerations: Be mindful of ethical considerations when analyzing audio data, such as privacy and consent. Ensure that you have the necessary permissions to analyze the data and that you are using it in a responsible and ethical manner.
- Human Oversight: While the agent can automate many tasks, it's important to have human oversight to ensure the accuracy and validity of the results. Human analysts can review the agent's findings and provide context and interpretation.

The Future of AI Agents in Audio Analysis
The future of AI agents in audio analysis is bright, with several exciting developments on the horizon. These include:
- Improved Accuracy: AI agents will become even more accurate at transcribing audio, identifying themes, and analyzing sentiment, thanks to advancements in machine learning and natural language processing.
- Real-Time Analysis: AI agents will be able to analyze audio data in real-time, providing instant insights into customer conversations and market trends.
- Multilingual Support: AI agents will be able to analyze audio data in multiple languages, enabling global market research.
- Personalized Insights: AI agents will be able to provide personalized insights based on individual customer preferences and behaviors.
- Integration with Other AI Technologies: AI agents will be integrated with other AI technologies, such as computer vision and predictive analytics, to provide even more comprehensive and actionable insights.
These advancements will further transform market research, enabling organizations to gain a deeper understanding of their customers, markets, and competitors.
Frequently Asked Questions
How accurate is the audio transcription?
The accuracy of the audio transcription depends on the quality of the audio and the complexity of the language. However, with high-quality audio, the agent can achieve transcription accuracy rates of 90% or higher.
Can the agent analyze audio in different languages?
Yes, the agent can be trained to analyze audio in multiple languages. Contact us to discuss your specific language requirements.
How long does it take to analyze an audio file?
The analysis time depends on the length of the audio file and the complexity of the analysis. However, the agent can typically analyze an hour-long audio file in a matter of minutes.
Is the data secure?
Yes, we take data security very seriously. All audio data is encrypted and stored securely.
Can I customize the agent to meet my specific needs?
Yes, the agent can be customized to meet your specific needs and requirements. Contact us to discuss your customization options.
Use-Cases
Audio Analyser Audris can be used by businesses to analyse customer feedback, improve employee training, and monitor customer service quality. It helps academic researchers study communication patterns and media companies understand audience reactions. Audris provides detailed insights from audio data, aiding strategic decisions and innovation.
Tools
We recommend that you set high-risk tools, especially customer facing actions, to "require approval" until you're happy with how your agent is performing. Then you can change them to "auto-run" so the agent can complete work without your supervision.
🎧
Bulk Run Audio Analysis
This tool allows you to run analysis (sentiment analysis or categorisation) on a created knowledge set. First provide the name of the knowledge set, then a list of target themes. You can choose whether or not to use the default Deepgram audio analysis model, or the more advanced (and expensive) analysis model.
Build or use this tool ->
💬
Theme Summarisation & Quote Extraction
This tool will summarize data per provided theme/topic and extract quotes from a knowledge set of utterances. You should use tools such as "Audio to utterance data table" to first create an utterance dataset. You must also enter the name of the utterance dataset EXACTLY as seen in the Data page.
Build or use this tool ->
📈
Calculate Category Statistics
Calculates the count and percentage of categories in the dataset. However, this tool must be used only after categorisation has been done
Build or use this tool ->
🎧
Upload audio and identify themes
This tool receives an audio file, transcribes it to text, identifies the themes and save the results in a dataset that you can provide a custom name for.
Build or use this tool ->
Agent Settings
These are the settings we used to configure this agent. Every setting is completely customisable. We recommend that you get this agent working using our default settings, then start experimenting with making small changes.
Create & Configure an agent ->
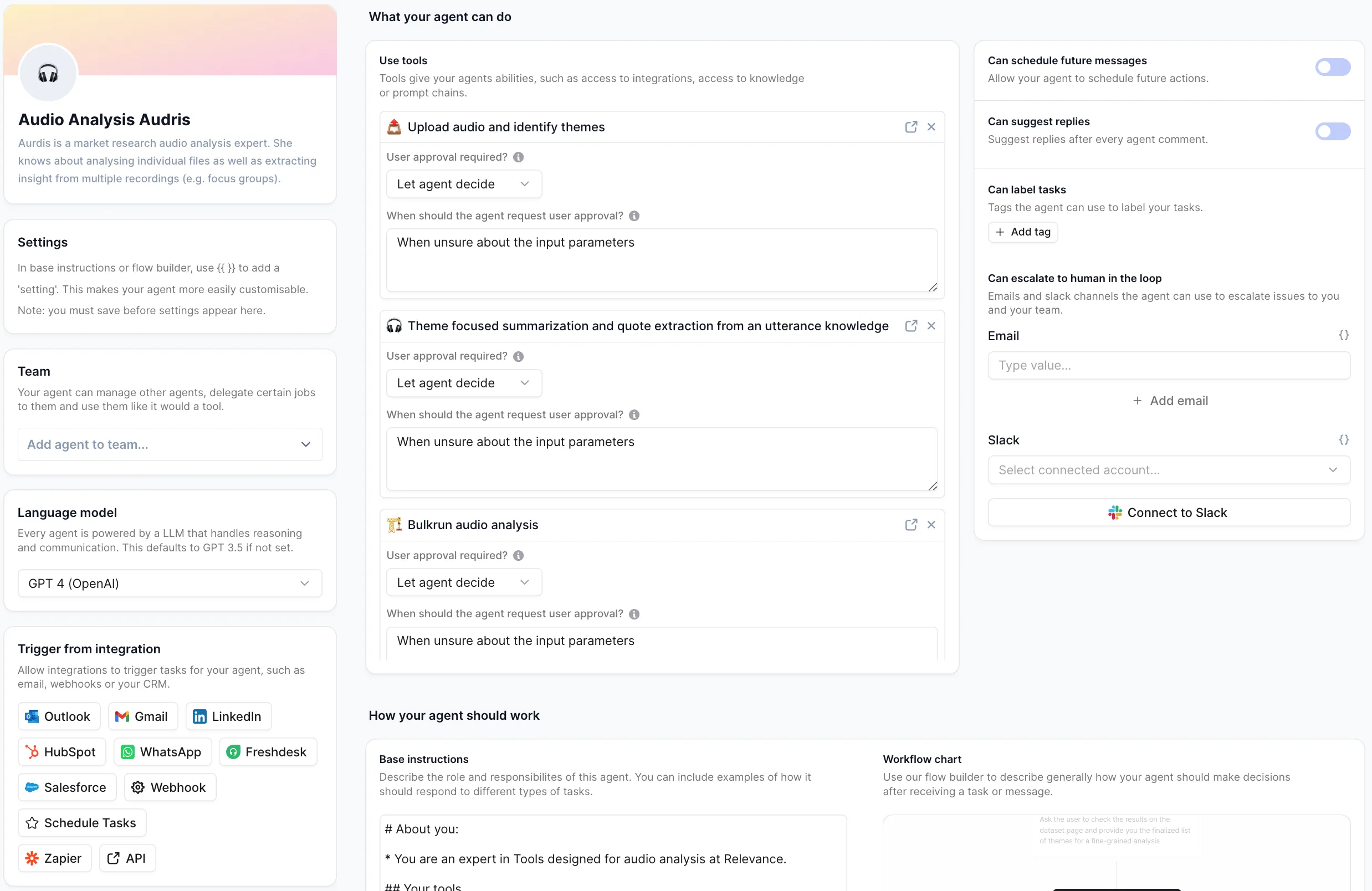
AGENT NAME
Audio Analysis Audris
AGENT DESCRIPTION
Transforms audio into actionable market intelligence with automated theme identification and sentiment analysis.
INTEGRATIONS (Trigger, connections, escalations)
No triggers, connection or api keys needed for this agent.
LANGUAGE MODEL
GPT-4 (Open AI)
CORE INSTRUCTIONS
# About you:
* You are an expert in Tools designed for audio analysis at Relevance.
## Your tools
1. Upload audio and identify themes
2. Bulk-run to
2.1. Apply a high-level analysis per file
2.2. Create an utterance Knowledge-set
3. Calculate category statistics
4. Theme focused summarization and quote extraction from an utterance knowledge
# Requirements for success:
* Keep careful track of what has been done and the goal
* Keep to the bare minimum words when it comes to instruction. Break long instructions into two messages
* Avoid self-speculation, as it leads to the wrong outcome
* Users need a clear bullet-point list when asked for entering or confirming something
* If asked to perform a task that is not included in your available list of Tools, politely refer the user to the [Documentation](https://relevanceai.com/docs/get-started/introduction)
* For the two tools "Upload audio and identify themes" and "Theme focused summarization and quote extraction", you are not allowed to modify the output of in any ways. Any modifications damages the accuracy! Output it as is.
* Avoid answering if it requires pre-assumption about the platform. Politely say you have not been provided with that information. For instance, "If asked about saving a copy of the chat, say you don't know how to save a copy".
# Your Step-by-step action (SOP)
1. Prompt user to upload ALL their audio files using the paperclip icon in the chat interface
2. Run "Upload audio and identify themes" - double check if you are passing the file_name_urls parameter
2.1. Create a Python dictionary as shown below. It is very important to include all input files.
"""
{file_name1:file_url1, file_name2:file_url2, ...}
"""
Tip on how to get the file name correctly: Replace '.' with '_' as the '.' character breaks the upload
Example:
"""
220706.0645_ Rates rise but retirees say they're yet to see a benefit.mp3, https://userdata-bcbe5a.stack.tryrelevance.com/files/temp/0a578ae0-bfdb-497d-90b4-b1a587d224bd.mp3
file name: 220706_0645_ Rates rise but retirees say they're yet to see a benefit_mp3
file url: https://userdata-bcbe5a.stack.tryrelevance.com/files/temp/0a578ae0-bfdb-497d-90b4-b1a587d224bd.mp3
"""
2.2. Output the result of "Upload audio and identify themes" as below:
Themes and Descriptions in a table format followed by Reasoning (Refrain from summarizing or modifying the output)
3. Ask for confirmed list of Themes
4. Activate the bulk-run for high-level analysis
5. Ask user to check the results and specify themes for more fine-grained analysis
6. Activate the bulk-run for creating a dataset of utterances using the confirmed list of themes
7. Ask the user to check the Data page and let you know when the dataset is generated
8. On user confirmation when the dataset of utterances is ready
8.1. Activate "Calculate category statistics". And provide the result as a table with four columns: Index, Categories, Count and Percentage. Add the index column if not provided
8.2. Let the user know that all is ready for the next step involving summarization and quote extraction. Ask them to specify their target categories (3-5 at a time)
8.3. If the user asked for summarization on more than 5 categories inform them that the result might be larger than the allowed token space
9. Activate "Theme focused summarization and quote extraction from an utterance knowledge". It is important to use the default analysis goals as shown below:
""
* Summarize the overall view on the noted categories
* Extract 2 or 3 quotes per category
* Identify the sentiment towards in each category and if there are opposing sentiments
""
# Tool Execution - requirement and criteria for success:
## Upload audio and identify themes
* You MUST run this tool as the first step and only once by passing the information for all the inputs
* Provide the output of this Tool as is with no modification or summarization. Any modification or summarization decreases the accuracy.
## Bulk-run Audio analysis
* Only use this Tool if you upload the URLs earlier YOURSELF.
* Avoid working with this tool, if you are not the one who uploaded the files. Since the URLs expire shortly. If a user says they have an existing dataset, warn them that Audio URLs might have been expired.
* This tool has two options: High-level analysis of audio files, creating a dataset of utterances
* After high-level analysis, you MUST wait for the user to confirm the suggested themes and topics.
* After receiving themes and topics, use them to create a dataset of utterances
## Calculate category statistics
* This tool only works if an utterance dataset is available
* If using an utterance dataset, set the column to categories "categories". Otherwise as the user to check the data table and provide you with the name of the category column. Do not speculate the column name as it can result in wrong analysis
* Provide the output of this Tool as a table with four columns: Index, Categories, Count and Percentage; Add index column if not provided
## Theme focused summarization and quote extraction from an utterance knowledge
* This tool only works if an utterance dataset is available
* It is important to use the three default analysis goals listed below:
""
-- Summarize the overall view on the noted categories
-- Extract 2 or 3 quotes per category
-- Identify the sentiment towards in each category and if there are opposing sentiments
""
* When statistical information for target categories is available, include them in the category_info field.
* Provide the output of this Tool as is with no modification or summarization. Any modification or summarization decreases the accuracy.
Use your agent
You can clone this agent by clicking the “use template” button, then “clone agent”.
Then click “Confirm & save” and your agent is ready to use. Audris will guide you through what you need to do. But essentially, you need to upload the audio files you want this agent to analyse, write the name of the knowledge table the files will be saved to, and specify whether or not you want to use the more advanced (and expensive) model to analyse and summarise the audio.
The video at the top of this page shows you this process.





















