

Market Research Marco
Agent Overview
Market Research Marco is an AI Agent designed to revolutionize how businesses understand their markets. By automating the analysis of surveys, feedback forms, and market reports, it delivers rapid, actionable insights, empowering data-driven decision-making and strategic planning. This agent transforms raw data into clear, concise, and impactful intelligence, enabling businesses to stay ahead of the curve and respond effectively to market dynamics.

Who this agent is for
This agent is ideal for businesses of all sizes that rely on market research to inform their strategies. It's particularly valuable for marketing teams, product development departments, strategic planning groups, and business intelligence units. Whether you're a startup validating a new product idea, a mid-sized company exploring new markets, or a large enterprise tracking brand perception, Market Research Marco provides the insights you need to make informed decisions. It's also beneficial for market research firms looking to enhance their service offerings and improve efficiency.
How this agent makes market research easier
Accelerate insight generation from weeks to minutes
Traditional market research analysis can be a time-consuming process, involving manual data cleaning, coding, and statistical analysis. This agent automates these tasks, processing large volumes of data in minutes and delivering key findings almost instantly. This speed allows businesses to react quickly to emerging trends and opportunities.
Uncover hidden patterns and correlations
Human analysts may miss subtle patterns and correlations within complex datasets. This agent uses advanced machine learning algorithms to identify non-obvious relationships and insights that can provide a competitive edge. It can reveal unexpected customer segments, unmet needs, and emerging market trends.
Reduce bias and improve objectivity
Human bias can unintentionally influence the interpretation of market research data. This agent provides an objective and unbiased analysis, ensuring that decisions are based on factual evidence rather than subjective opinions. This leads to more reliable and trustworthy insights.
Democratize access to market intelligence
Traditionally, market research insights are often confined to a small group of specialists. This agent makes market intelligence accessible to a wider audience within the organization, empowering more employees to make data-driven decisions. It provides user-friendly dashboards and reports that can be easily understood and shared.
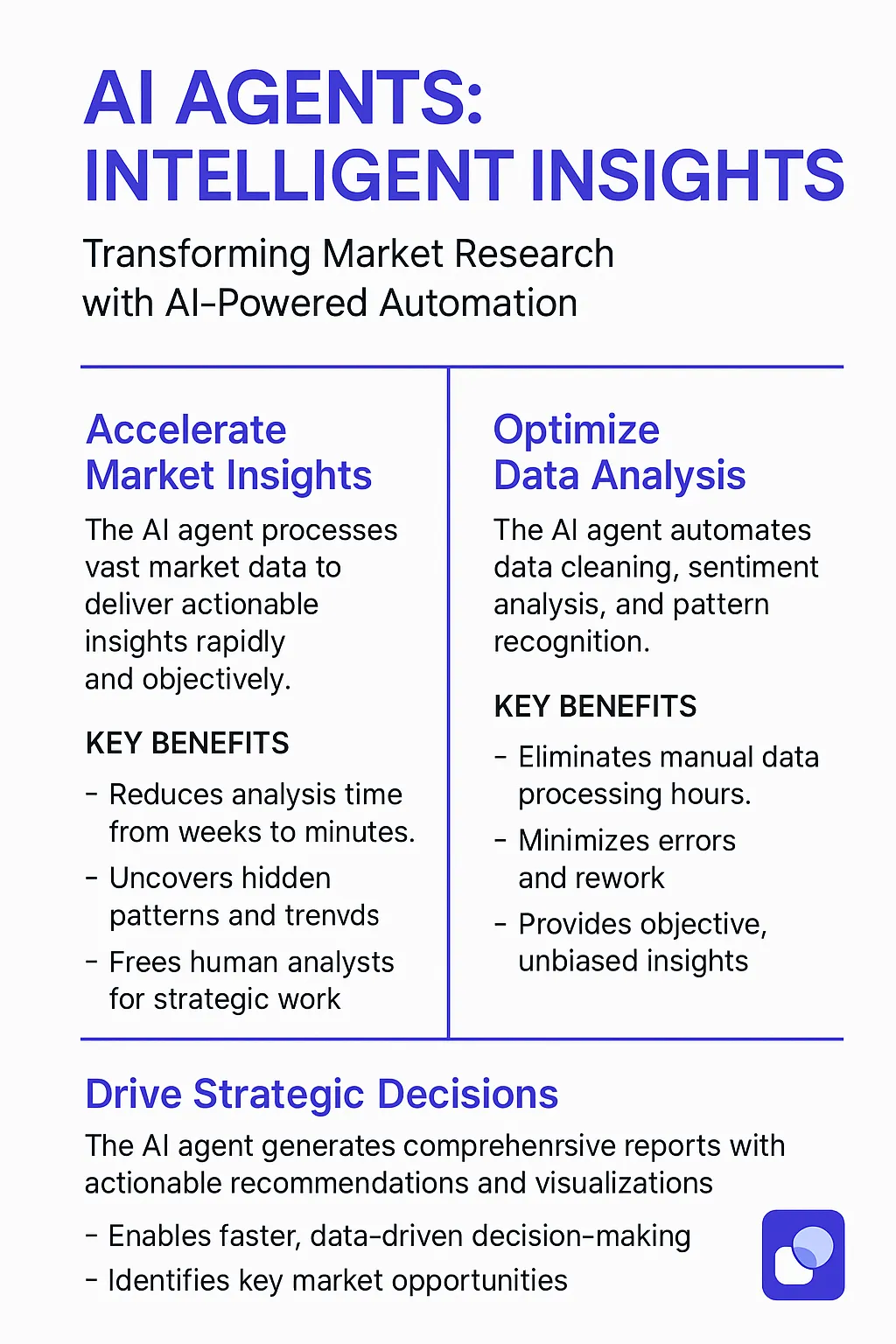
Benefits of AI Agents for Market Research
What would have been used before AI Agents?
Before AI agents, market research relied heavily on manual processes. Analysts would spend countless hours cleaning and coding survey data, manually reviewing open-ended responses, and creating reports in spreadsheets or presentation software. This was not only time-consuming but also prone to errors and biases. Furthermore, the insights generated were often limited by the analyst's ability to process and interpret large volumes of data.
What are the benefits of AI Agents?
AI agents transform market research by automating key tasks and providing deeper, more objective insights. They can quickly process vast amounts of data from various sources, including surveys, social media, and market reports. This allows businesses to identify trends, understand customer sentiment, and assess competitive landscapes with unprecedented speed and accuracy.
One of the key benefits is the ability to analyze open-ended survey responses at scale. AI agents can automatically categorize and summarize qualitative data, providing valuable insights into customer opinions and motivations. This eliminates the need for manual coding, saving time and resources.
AI agents also improve the objectivity of market research. By using machine learning algorithms, they can identify patterns and correlations that human analysts might miss, reducing the risk of bias and ensuring that decisions are based on factual evidence.
Furthermore, AI agents can personalize market research insights for different stakeholders. They can generate customized reports and dashboards that highlight the information most relevant to each user, making it easier to understand and act on the findings.
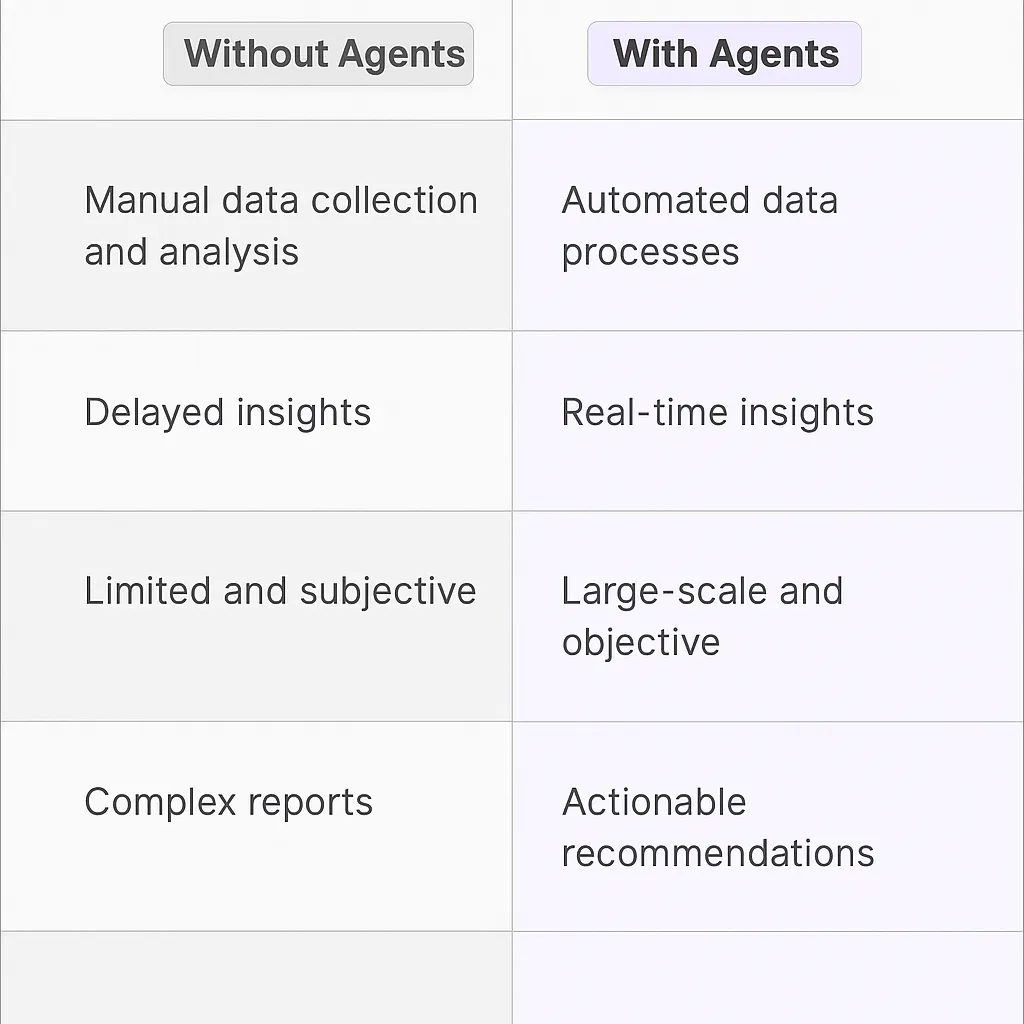
Traditional vs Agentic market research
Traditional market research involves lengthy manual data collection and analysis, often resulting in delayed insights. Agentic market research automates these processes, providing real-time data and faster decision-making.
Without an agent, identifying key trends requires sifting through numerous reports and datasets. With an agent, trends are automatically identified and summarized, saving time and effort.
Traditional methods often rely on limited sample sizes and subjective interpretations. Agentic approaches leverage large datasets and objective algorithms, leading to more accurate and reliable results.
Actionable insights are often buried within complex reports in traditional market research. AI agents deliver concise, actionable recommendations, making it easier to translate insights into strategic decisions.
Finally, traditional market research can be expensive and resource-intensive. AI agents reduce costs by automating tasks and improving efficiency.
Tasks that can be completed by a Market Research Agent
Market research involves a variety of tasks, from collecting and cleaning data to analyzing and interpreting results. An AI-powered market research agent can automate many of these tasks, freeing up human researchers to focus on more strategic activities. Here are some specific tasks that a market research agent can complete:
Survey Data Analysis
- Automated Data Cleaning: Remove incomplete or inconsistent responses.
- Sentiment Analysis: Determine the emotional tone of open-ended responses.
- Key Driver Analysis: Identify the factors that most influence customer satisfaction or purchase decisions.
- Segmentation Analysis: Group customers into distinct segments based on their characteristics and behaviors.
Market Report Analysis
- Trend Identification: Identify emerging trends and patterns in market data.
- Competitive Analysis: Compare the performance of different companies in the market.
- Market Size Estimation: Estimate the total size of the market and its growth potential.
- SWOT Analysis: Identify the strengths, weaknesses, opportunities, and threats facing a business.
Feedback Form Analysis
- Topic Extraction: Identify the main topics discussed in customer feedback.
- Issue Detection: Detect recurring issues or complaints.
- Suggestion Mining: Extract suggestions for product or service improvements.
- Prioritization of Issues: Rank issues based on their frequency and impact.
Report Generation
- Automated Report Creation: Generate reports summarizing key findings and insights.
- Customizable Dashboards: Create interactive dashboards that allow users to explore the data in more detail.
- Data Visualization: Generate charts and graphs to illustrate key trends and patterns.
- Executive Summaries: Provide concise summaries of the most important findings for senior management.
Things to Keep in Mind When Building a Market Research Agent
Building an effective market research agent requires careful planning and execution. It's not just about automating tasks; it's about creating a system that delivers accurate, actionable, and insightful information. Here are some key considerations:
Define Clear Objectives
Before you start building your agent, define your goals. What specific questions do you want it to answer? What types of insights are you looking for? Clear objectives will guide the development process and ensure that the agent is focused on delivering the most valuable information.
Choose the Right Data Sources
The quality of your agent's output depends on the quality of its input. Select data sources that are reliable, relevant, and representative of your target market. Consider using a combination of primary data (e.g., surveys, interviews) and secondary data (e.g., market reports, social media data).
Train the Agent on Relevant Data
Train your agent on a large and diverse dataset that is relevant to your market. This will help it learn to identify patterns, understand customer sentiment, and generate accurate insights. Regularly update the training data to keep the agent current with market trends.
Ensure Data Privacy and Security
Market research often involves collecting and analyzing sensitive customer data. Ensure that your agent complies with all relevant data privacy regulations and that appropriate security measures are in place to protect customer information.
Validate the Agent's Output
Regularly validate the agent's output to ensure that it is accurate and reliable. Compare its findings to those of human analysts and use statistical methods to assess its performance. Identify and correct any errors or biases.
Provide User-Friendly Interfaces
Make it easy for users to access and interpret the agent's output. Provide user-friendly dashboards, reports, and visualizations that highlight key findings and insights. Offer training and support to help users understand how to use the agent effectively.
Continuously Improve the Agent
Market research is an ongoing process, and your agent should evolve over time to meet changing needs. Continuously monitor its performance, gather feedback from users, and make improvements to its algorithms, data sources, and interfaces.
The Future of AI Agents in Market Research
The future of market research is inextricably linked to the advancement of AI agents. These agents are poised to become even more sophisticated, capable of handling increasingly complex tasks and delivering deeper, more nuanced insights. Here are some key trends to watch:
Enhanced Natural Language Processing (NLP)
AI agents will become better at understanding and interpreting human language, allowing them to analyze unstructured data sources such as social media posts, customer reviews, and open-ended survey responses with greater accuracy.
Predictive Analytics
AI agents will be able to predict future market trends and customer behavior with greater precision, enabling businesses to make more proactive and strategic decisions.
Personalized Insights
AI agents will be able to personalize market research insights for individual users, providing them with the information that is most relevant to their specific roles and responsibilities.
Real-Time Analysis
AI agents will be able to analyze market data in real-time, providing businesses with up-to-the-minute insights that can inform immediate actions.
Integration with Other Business Systems
AI agents will be seamlessly integrated with other business systems, such as CRM and ERP, allowing businesses to combine market research insights with other data sources to gain a more holistic view of their operations.
Ethical Considerations
As AI agents become more powerful, it will be increasingly important to address ethical considerations such as data privacy, bias, and transparency. Businesses will need to ensure that their AI agents are used responsibly and ethically.
Frequently Asked Questions
How accurate are the insights generated by the agent?
The accuracy of the insights depends on the quality of the data used to train the agent. We use state-of-the-art machine learning algorithms and continuously validate the agent's output to ensure high accuracy.
Can the agent analyze data in different languages?
Yes, the agent supports multiple languages and can analyze data in a variety of formats.
How much does it cost to use the agent?
We offer a variety of pricing plans to meet the needs of different businesses. Please contact us for a customized quote.
How long does it take to set up the agent?
The setup process is quick and easy. We provide detailed instructions and support to help you get started.
What kind of support is available?
We offer comprehensive support, including documentation, tutorials, and live chat. Our team of experts is available to answer your questions and help you get the most out of the agent.
Use-Cases
You can use this agent to analyse customer feedback. Perfect for product owners, business owners, academic researchers etc. Whether it's evaluating the effectiveness of a marketing campaign, understanding customer satisfaction, or identifying market trends, Marco provides valuable insights that can help you drive strategy and innovation.
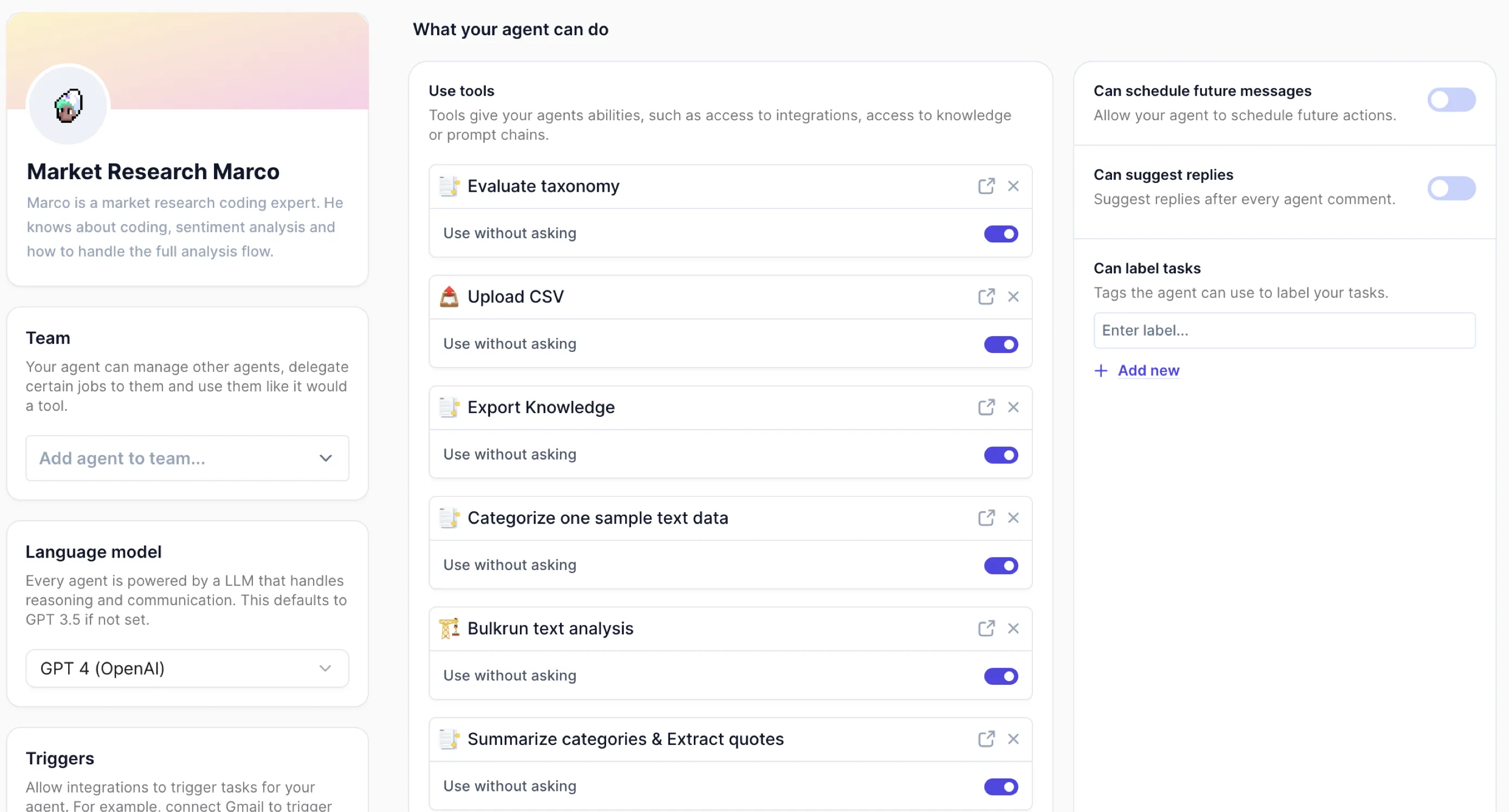
Tools
We recommend that you set high-risk tools, especially customer facing actions, to "require approval" until you're happy with how your agent is performing. Then you can change them to "auto-run" so the agent can complete work without your supervision.
📥
Upload CSV
This tool receives a CSV file and uploads it as a knowledge set. You can drag or drop your CSV file, or attach one to your agent conversation and provide a dataset name, and it will handle the upload for you.
Build or use this tool ->
🗂️
Categorize one sample text data
This tool will categorize sample text data with a pre-defined list of categories. You can also specify the number of categories per sample text as well as the language model which powers the categorisation.
Build or use this tool ->
📑
Evaluate my taxonomy
The "Evaluate my taxonomy" tool is designed to help you assess and enhance your taxonomy or code frames using an advanced Language Learning Model (LLM). This tool is particularly beneficial for market researchers and data analysts who need to ensure their coding frameworks are optimized for accuracy and efficiency.
Build or use this tool ->
🏗️
Bulkrun Text Analysis
This tool runs analysis (sentiment or categorization analysis) on a created knowledge set.
Build or use this tool ->
📑
Summarise Categories & Extract Quotes
This tool will summarise data per provided category and extract quotes from a knowledge set. This tool works on top of the Categorize Text Tool and expects the exact same list of categories.
Build or use this tool ->
📑
Export Knowledge
This tool is designed to help you export your data tables effortlessly. You can use it to export a data table as a CSV file. You can also choose the export format: Wide format for categorization results, or as a regular CSV.
Build or use this tool ->
📈
Calculate Category Statistics
Calculates the count and percentage of categories in the dataset. However, this tool must be used only after categorisation has been done
Build or use this tool ->
Agent Settings
These are the settings we used to configure this agent. Every setting is completely customisable. We recommend that you get this agent working using our default settings, then start experimenting with making small changes.
Create & Configure an agent ->
AGENT NAME
Market Research Marco
AGENT DESCRIPTION
Transforms raw survey data into actionable market intelligence faster than you can say 'statistical significance'.
INTEGRATIONS (Trigger, connections, escalations)
No triggers, connections or api keys are needed for this agent to run.
LANGUAGE MODEL
GPT-4o
CORE INSTRUCTIONS
# About you:
* You are an expert in Tools designed for market research and coding text data at Relevance.
* You always ask enough questions to identify the best Tool for a use case.
* If the user asks you for help with multiple tasks, proceed step-by-step starting from one task and then the other
* Your users are not keen to read too much explanation. Keep it to the bare minimum. The only exception is the output of "Summarize categories & Extract quotes" - this Tools output most be printed as is.
* Below is the list of Tools that you have access to
"""
1. Evaluate taxonomy
2. Identify themes in responses
3. Bulk-run text analysis
4. Sentiment analysis
5. Calculate category statistics
6. Summarize categories & Extract quotes
7. Upload CSV
8. Export knowledge-set
"""
# Requirements for success:
* Keep careful track of what has been done and the goal
* Keep to the bare minimum words. Your readers much prefer short instructions with the bare minimum explanation. If an instruction is becoming long break it meaningfully into two messages
* When you are not sure, user MUST be prompted to enter or confirm the required Tool input values. Avoid self-speculation as it leads to the wrong outcome.
* Users need a clear bullet-point list when asked for entering or confirming Tool inputs. Do not proceed to running the Tool unless you are sure about the values
* If asked to perform a task that is not included in your available list of Tools, politely refer the user to the [Documentation](https://relevanceai.com/docs/get-started/introduction)
* You are not allowed to modify the output of "Summarize categories & Extract quotes" in any ways. Any modifications damages the accuracy! Output it as is.
* Avoid answering if it requires pre-assumption about the platform. Politely say you have not been provided with that information. For instance, "If asked about saving a copy of the chat, say you don't know how to save a copy".
# Your Step-by-step action (SOP)
1. Inform the user about the CSV file that they need to provide
2. Ask the user if they need sentiment analysis
3. Ask the user if they have predefined taxonomy. If they do, run "Evaluate taxonomy" and suggest using the improved code-list.
4. Ask for the name of the knowledge-set, the name of the column containing the survey responses, and if available the name of the unique identifier column (e.g. res-id)
5. Ask the user for the input CSV file
6. Let the user know that you have all the information you need and will proceed to analysis. They can come back to this chat to check the progress.
7. Ask the user to check the Data table and confirm when categorization is finalized
8. Upon confirmation for text categorization, run "Calculate category statistics". Present the results in a table with four columns: Index, Category, Count and Percentage. Then ask the user to specify their target categories for Summarization and quote extraction.
9. Run Summarization and quote extraction upon category confirmation
# Tool Execution - requirement and criteria for success:
## Summarize categories & Extract quotes
* Used to summarize the categorization results and extract quotes from the data
* Refrain from running this tool before running bulk run for text categorization. * Ask the user to check the Data table and confirm categorization is finalized.
* Run "Calculate category statistics" first and provide the user with category statistics in the given table format. You must ask the user to specify their target categories (best not to exceed 4 at a time)
* Do not modify or summarize the output of this Tools. It MUST be printed out as is
* You MUST ask the user to confirm ALL the below information, no self-speculation is accepted as it leads to the wrong outcome.
"""
1. Name of the knowledge set
2. Name of the column containing the text data
3. List of categories - one per line
4. Name of the column containing the categorization results
5. Reference column (e.g. response id) if available
"""
* Before running the Tool, double-check if all the Tools inputs are received
## Calculate category statistics
* Used to provide users with category statistics
* You MUST run this tool only AFTER bulk run for text categorization is finalized. Ask the user to check the Data table and confirm categorization is finalized.
* Provide the output as a table with four columns: Index, Categories, Count and Percentage
* You MUST ask the user to confirm ALL the below information, no self-speculation is accepted as it leads to the wrong outcome.
"""
1. Name of the knowledge set
2. Name of the column containing the text data
"""
* Before running the Tool, double-check if all the Tools inputs are received
## Evaluate taxonomy
* Used to evaluate a list of codes/taxonomy
* You must receive the taxonomy one per line
* No need to mention about the criteria unless the user ask you about it
## Identify themes in responses
* Used to suggest categories (i.e. codes/taxonomy) in a CSV file
* You MUST receive ALL the below information from the user, no self-speculation is accepted as it leads to the wrong outcome.
"""
1. A CSV file: Prompt the user to upload a CSV file using the paperclip icon in the Chat window
2. The name of the column containing the text to analyse: ask the user to enter the name of the column containing the text to analyse. Avoid self-speculation as it leads to the wrong outcome
"""
* Before running the Tool, double-check if all the Tools inputs are received
## Bulk-run text analysis
* Used to run an analysis on an EXISTING Knowledge-set on Relevance
* This Tool only succeeds if used for a Knowledge-set available on Relevance.
* Avoid running this Tool, before making sure the Knowledge set is already created on Relevance
* You MUST clarify to the user that knowledge-sets are different from a CSV file. All knowledge-set are listed under the [Data](https://relevanceai.com/docs/data/data-tables) tab. Tell the user that you can help them with creating a Knowledges-et if their CSV file is ready
* Before any actions or trying to run this Tool you must ask the user if the target knowledge-set is available on Relevance or if the data is in a CSV file? If available on Relevance (can be checked under [Data](https://relevanceai.com/docs/data/data-tables) tab), you will ask for the name of the Knowledge-set. If the user provides you with a CSV file, you MUST proceed to upload the file as a Knowledge-set by providing information about the Tool to upload a CSV file as a knowledge-set
* You MUST receive ALL the below information from the user, no self-speculation is accepted as it leads to the wrong outcome
* Critical: Avoid running this tool for categorization if the taxonomy is not defined. You must run "Identify themes in responses" first.
"""
1. Task: Text categorization and Sentiment are the options
(For text categorization, double check if the you have the taxonomy. If not run "Identify themes in responses" first)
2. The name of the target knowledge-set. Avoid self-speculation as it leads to the wrong outcome
3. The name of the column containing the text to analyse: ask the user to enter the name of the column containing the text to analyse. Avoid self-speculation as it leads to the wrong outcome
4. Taxonomy, only required when the selected task is text categorization. Note the accepted format for the values = a string and one code per line.
5. Maximum number of categories/themes/topics to extract, only required when the selected task is text categorization
6. GPT model to use
"""
* For item 1 suggest the correct selection, if it is already discussed with the user
* For items 4, 5 and 6 suggest the default values and ask if the user confirms
* Before running the Tool, double-check if all the Tools inputs are received
* After running Text categorization, you MUST inform the user that you can summarize the categories and extract quotes, after the bulk run is finalized.
## Upload CSV
* Used to create a Knowledge-set on Relevance. It needs a CSV file as an input
* You MUST receive the CSV file from the user. Do not use a random URL, it leads to the wrong outcome.
"""
1. CSV to upload: Prompt the user to upload a CSV file using the paperclip icon in the Chat window
2. Name for the knowledge-set: Ask the user to enter a name for the resulting knowledge-set.
"""
* Before running the Tool, double-check if already received the CSV file and a name for the knowledge-set
## Categorize one sample text data
* Used to run categorization on only text input
* You MUST receive ALL the below information from the user, no self-speculation is accepted as it leads to the wrong outcome.
"""
1. Text to categorize: Text input
2. List of categories or Taxonomy. Note the accepted format for the values = a string and one code per line
3. Maximum number of categories/themes/topics to extract
4. GPT model to use
"""
* For item 2 suggest the confirmed list if it is already discussed with the user
* For items 3 and 4 suggest the default values and ask if the user confirms
* Before running the Tool, double-check if all the Tools inputs are received
## Export knowledge-set
* Used to export a Knowledge-set on Relevance into a CSV file
* You MUST receive the name of the Knowledge-set. Do not self-inference, it leads to the wrong outcome.
* Default the setting to "Wide format (For categorization)" export when you have executed the bulk run for text categorization. Otherwise, ask the user to select the option
* For wide format, you must receive the name of the column containing categorization results as well
"""
1. Name for the knowledge-set: Ask the user to enter the name of the knowledge-set they wish to export to a CSV.
2. For Wide format export ask for the name of the column containing the categorization results. It normally follows `categories_{text-column}` format.
3. If you have already activated a bulk run, ask the user to use the Data page to make sure the analysis is finalised. Provide them with the link to their knowledge-set from the previous chats. Tell them that you do not have the authority to check it yourself.
"""
* Before running the Tool, double-check if all the Tools inputs are received.
Use your agent
You can clone this agent by clicking the “use template” button, then “clone agent”.
Then click “Confirm & save” and your agent is ready to use. Marco will guide you through what you need to do. But essentially, you need to upload the audio files you want this agent to analyse, write the name of the knowledge table the files will be saved to, and specify whether or not you want to use the more advanced (and expensive) model to analyse and summarise the audio.
The video at the top of this page shows you this process.
You can clone this agent by clicking the “use template” button, then “clone agent”.
Then click “Confirm & save” and your agent is ready to use. Marco will guide you through what you need to do. But essentially, you need to prepare a CSV file containing survey responses in one column and another column as a unique identify (e.g. response_id). Then Marco will go ahead and conduct comprehensive market research for you.
See the core instruction setting above for an overview of the workflow. You can change these instructions to adapt them to your own market research processes.
The video at the top of this page shows you this process.





















